[IT비즈뉴스 최태우 기자] 마인즈랩이 여러 명의 발화가 동시 이뤄진 음성을 화자별로 분리하는 음성 분리·필터(Voice Filter) 기술 구현에 성공했다. 마인즈랩은 해당 기술을 오픈소스로 공개했다.
음성 분리·필터 기술은 토론회와 같이 다수의 화자가 겹쳐서 동시에 발화하는 음성이 있을 때 화자별로 음성을 각각 분리할 수 있는 딥러닝 기술이다. 앞서 구글이 지난해 10월 관련 기술 논문을 공개한 적이 있다.
5일 마인즈랩에 따르면 자사 브레인팀에서 음성 분리·필터 기술을 구현한 게 이번이 세계 최초 사례다. 해당 기술은 오픈소스로 공개됐다. 사측은 다중 화자 음성인식이 필요한 분야에 걸쳐 기술적 한계로 구현이 힘들었던 음성인식 솔루션의 고도화도 가능해질 것으로 기대하고 있다.
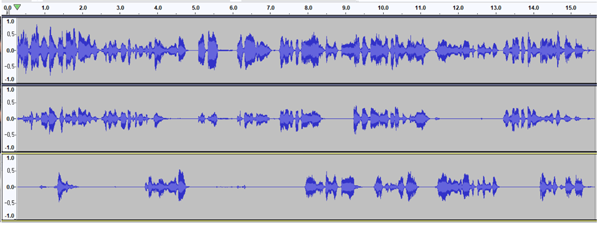
음성 분리·필터 기술은 회의록의 자동 작성과 전사와 같이 고도화된 음성인식 기술이 필요한 분야에서 다양하게 상용화될 수 있다. 사측은 관련 기술을 인공지능(AI) 회의록 서비스와 하이브리드 고객센터 서비스에 적용, 강화할 계획이다.
마인즈랩의 브레인팀을 이끌고 있는 최홍섭 상무는 “해당 기술을 통해 3명 이상의 화자까지 분리하는 데 성공했다”며 “현재 공공·민간 분야 모두에서 회의록 자동 작성에 대한 기술 수요가 높은 상황인데 이에 빠르게 대처할 수 있게 된 것은 물론 보다 고도화된 음성인식 서비스로 갈 수 있는 R&D 성과로 보고 있다”고 말했다.