![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202203/65720_60530_401.jpg)
‘감성 분석(Sentiment Analysis)’이란 자연어처리 기술을 사용하여 문장 혹은 문서에서의 표현이 긍정, 부정 혹은 중립인지를 판별하는 기술이다.
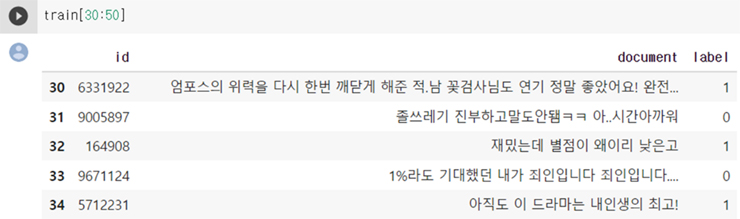
아래 그림 1과 같이 약 15만건의 훈련용 데이터세트의 각 행에 id 컬럼과 document 컬럼에 영화평과 label 컬럼에 1(긍정) 혹은 0(부정)의 정보가 들어있는 네이버의 영화평 코퍼스를 사용한 감성 분석을 살펴보자.
감성 분석의 처리 절차
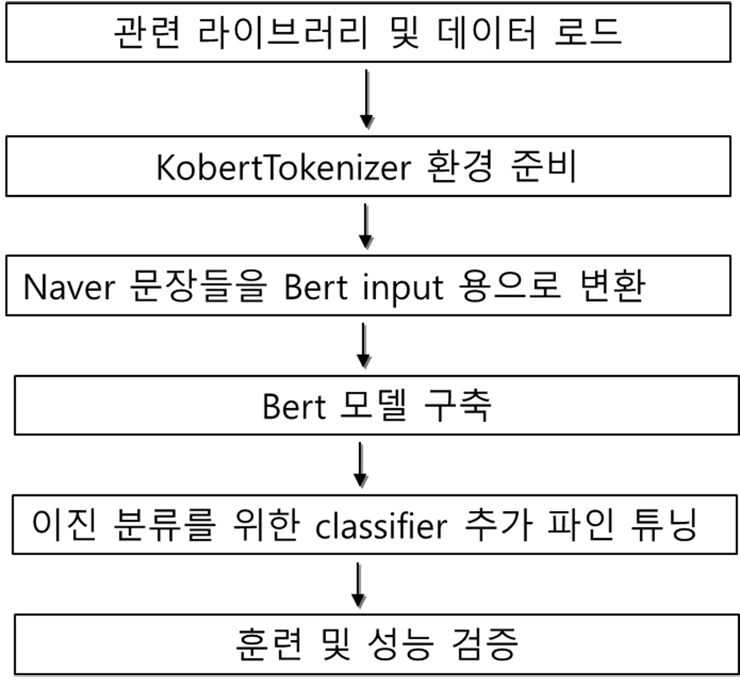
딥러닝(DL)을 통한 대략적인 감성 분석 처리 절차는 아래 그림2와 같다. Huggingface의 Kobert 사전학습 모델을 전이받아 훈련하는데 있어 수행은 Google Colab을 이용하였다.
Huggingface의 transformers를 import해 쓰려면 Tensorflow 2.5 이상이 필요하다. Huggingface는 BERT, BART, ELECTRA 등의 최신 자연어처리 알고리즘을 Tensorflow, Torch로 구현한 transformers repository를 제공하여 많이 사용한다.
최근 발표된 ‘Bert’라는 언어모델에 기반해서 한글 데이터세트에서 보다 좋은 성능을 보이는 Kobert 언어모델을 사용한다. 순서는 아래 그림 2와 같은 순서로 진행한다.
1. 관련 라이브러리와 네이버 영화평 코퍼스를 다운받는다.
2. 최신 tensorflow 버전 2.5 이상에서 동작하는 huggingface의 kobert tokenizer를 사용하기 위하여 이곳에서 KobertTokenizer 내용을 주피터 노트북 셀로 복사해 온다.
3. Bert 입력 형태로 네이버 영화평 데이터가 입력될 수 있도록 데이터 변환
4. Bert 사전학습 모델을 전이학습을 통한 모델 구축
5. 이 사전학습 모델 위에 긍정·부정 분류를 위한 이진(binary) 분류기의 층을 파인튜닝을 위해 추가
6. 모델 훈련 및 평가
Bert 언어모델
2020년 구글이 공개한 AI 언어모델 BERT(Bidirectional Encoder Representations from Transformers)는 일부 성능 평가에서 인간보다 더 높은 정확도를 보이는 AI 기반 최첨단 DL모델이다.
언어 모델이란 자연어의 법칙을 컴퓨터로 모사한 모델인데, 보통 주어진 단어들로부터 그 다음에 등장할 단어의 확률을 예측하는 방식으로 학습되면서 다음에 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이고 문맥을 잘 계산하는 좋은 언어 모델로 간주한다.
가령 구글의 검색 창에서 “딥러닝을 이용한”이라는 문장을 치면 다음에 이어서 화면에 나타나는 문장들을 보고 얼마나 우리말에 자연스럽고 합당한 문장이 이어지는가를 보는 것과 같다.
2017년 이전의 자연어처리에서 주로 사용되어 온 재귀신경망(Recurrent Neural Network) 구조를 완전히 배제하고 attention만으로 이전의 자연어처리의 문제점들을 극복한 transformer라는 획기적인 구조가 발표된 후 구글은 Bert를 발표한다. Bert는 transformer 의 인코더-디코더 구조 중에 인코더만을 사용한다.
Bert는 약 30억 어절의 영어데이터와 3만개의 토큰을 사전으로 활용하여 ‘언어 이해’ 모델을 사전학습한다. 학습방법도 특징이 있는데, 우선 두 개의 문장을 문장 순서로 학습하여 두 번째 이어서 오는 문장이 순서에 맞는 문장인지를 학습한다. 또 양방향으로 학습하여 가려진 단어를 맞추는 방식으로 학습한다.
예를 들어, “저 남자는 (①)에 출근했다. 회사에 출근하자마자 (②)를 마셨다”라는 문장이 있을 때, ①번과 ②번 마스크에 대하여 ‘회사’와 ‘커피’라고 맞추는 방식의 훈련이다.
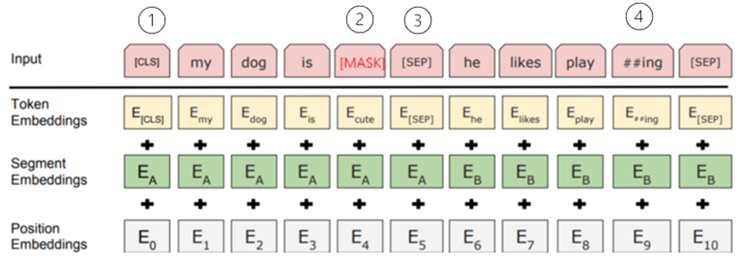
위의 그림3과 같이 이러한 Bert에 입력되는 두 개의 문장은 Token, Segment, Position이라는 임베딩이 단어 임베딩 단위로 이루어져 Bert에 입력된다.
이때 최종 입력되는 형태인 그림 최상단의 input을 보면 ①과 같이 문장 처음에 [CLS]가 삽입되고 ②와 같이 문장 일부를 가려(MASK)버리고, ③과 같이 문장과 다음 문장을 구별하는 [SEP] 구별자가 들어가고, ④와 같이 단어 임베딩으로 WordPiece tokenizer를 사용하는데playing이 ‘play’와 ‘##ing’로 어절이 분리된다.
- Token Embeddings는 Bert에 입력으로 들어가는 문장을 tokenizing 한 후, index 번호를 매긴 것
- Segment Embedding은 문장과 다음 문장을 구분하는 것
- Position Embedding은 입력되는 단어 위치를 내부적으로 자동 인식하기 위함
우리는 네이버의 한글 영화평 코퍼스를 입력데이터로 사용하기 때문에 네이버의 데이터 형식을 Bert가 인식할 수 있는 형태로 변환해야 하기 때문에 이렇게 Bert가 어떻게 학습되었는가에 맞추어 형식을 일치시켜야 한다.

Huggingface의 깃허브(github)를 보면 그림 4와 같이 모델 별F1 score를 볼 수 있다. Bert-Mutilingual 모델은 Bert를 147개국 언어에서 사용할 수 있도록 제공한 모델이다. 이렇게 단기간에 다양한 언어에 적용 가능한 것은 WordPiece 방식의 토크나이저 덕분이다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카
관련기사
- LG AI연구원, 초거대 AI '엑사원' 고도화에 GCP 클라우드 TPU 도입
- 네이버 클로바, 올해 글로벌 AI학회에서 정규 논문 66건 발표
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
- 엔비디아 잡겠다…英 팹리스 그래프코어, IPU-팟(POD) 앞세워 도전장
- 카카오엔터, 글로벌 AI 챌린지에서 2개 대회에서 1위 달성
- 인공지능(AI)을 활용한 객체탐지(Object Detection)는 어떻게 작동하나 ①
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?
- 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ②
- 딥러닝(DL)을 통한 한글 문장의 감성분석은 어떻게 이뤄지나 ②