![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202203/66222_61015_2718.jpg)
지난 글에서는 감정분석 처리의 절차와 버트(Bert) 언어모델에 대해 알아봤다. 이번 글에서는 한국어 언어모델과 이를 활용한 네이버 영화펑 코퍼스 로드에 대해 알아본다.
이전 기고문 확인하기
☞ 딥러닝(DL)을 통한 한글 문장의 감성분석은 어떻게 이뤄지나 ①
한국어 언어모델로 버트(Bert)를 대상으로 진행된 연구로는 이번 과제에서 사용되는 SKT브레인(SKT brain)의 코버트(Kobert)가 있다. 9,200만개 파라미터를 가지고 있으며 한국어 위키, 뉴스의 약 3억2000만개 단어를 훈련하였고 센텐스피스 토크나이저(sentencepiece tokenizer) 기반으로 어휘사전은 8,000여개이다.
서울대의 KR-BERT는 9,900만 파라미터를 가지고 있으며, 한국어 2억3000만개를 훈련하였고 양방향 워드피스 토크나이저(wordpiece tokernizer) 기반으로 어휘사전은 1만2367개다.
ETRI Bert는 한글 형태소 기반의 언어모델로 1억천만개 파라미터를 가지고 있으며, 47억개의 형태소를 학습하였고 한글 형태소기반 tokenizer를 사용한 어휘사전은 3만797개다.
이외에 삼성SDS의 코리알버트(KoreALBERT)는 44억개 단어를 훈련하였고 구글의 알버트(ALBERT) 언어모델에 기반한다. 토크나이저(Tokenizer) 역시 각 사가 다른 토크나이저(tokenizer)를 기반으로 하고 있다.
이번 과제에서는 SKT브레인의 센텐스피스 토크나이저(sentencepiece tokenizer)에 기반하고 허깅페이스(huggingface)에 등재된 코버트 토크나이저(Kobert tokenizer)를 사용하고자 한다.
형태소란 더 분석하면 뜻이 없어지는 말의 단위다. 한글은 교착어이므로 명사에 조사가 붙어있는 경우가 많고 복합명사도 많다. 그래서 의미 단위로 교착어를 분리시키면 좋은 tokenizer를 얻고 성능도 좋아진다. 그런 의미에서 ETRI의 형분석기 tokenizer는 한글 성능을 향상시킬 여지를 좀 더 가지고 있다고 볼 수 있다.
Tokenizer
토크나이저는 입력 문장을 단어 혹은 서브 단어 단위로 쪼갠 후 사전에 등록된 아이디로 변환해주는 과정이다.
[“Do”, “n’t”, “you”, “love”, “Bert”, “?”, “we”, “sure”, “do”, “.”]
위의 예는 단어 단위의 분절이지만, 문자 단위에 비해 어휘사전(vocab.txt)이 엄청 커지므로 메모리에 문제를 야기한다. 문자 단위 토크나이저는 단순하고 메모리를 적게 사용하지만, 문맥을 이해할 의미 있는 단위로 학습하는데 지장을 준다.
기계가 문제를 풀 때 모르는 단어가 등장하면 자연어처리가 까다로워진다. 이와 같이 모르는 단어로 인해 문제를 푸는 것이 어려워진 상황을 Out-Of-Vocabulary(OOV) 문제라고 한다.
서브 워드 분리 작업은 하나의 단어가 여러 서브 워드 들의 조합(예, birthplace = birth + place)으로 구성된 경우가 많기 때문에 하나의 단어를 서브 단어로 분리해서 인코딩 및 임베딩 하겠다는 의도를 가진 전처리 작업이다.
[“I”, “have”, “a”, “new”, “gp”, “##u”, “!”, ]
위의 예는 BertTokenizer 가 “I have a new GPU!”를 분절한 예이다. 서브 워드 분절은 의미 있는 단어 혹은 서브 워드 단위의 표현을 학습하면서도 합리적인 사전(vocabulary)크기를 유지할 수 있다는 점이 큰 장점이다. Byte-pair-encoding(BPE)는 우선 단위 출현 빈도수를 사전 토큰화 한다. 즉 아래와 같이 ‘hug’ 나 ‘pug’ 등의 빈도 수를 표시한다.
( ‘hug’, 10), (‘pug’, 5), (‘pun’, 12), (‘bun’, 4), (‘hugs’, 5)
이후 위의 분절에서 가장 많이 등장하는 문자 쌍을 찾아 어휘사전에 등록하고 치환된 단어 분절을 계속 빈도 수에 따라 계속 결합해 나간다.
(‘h’ ‘ug’, 10) (‘p’ ‘ug’, 5) (‘p’ ‘un’, 12) (‘b’ ‘un’, 4) (‘hug’ ‘s’ , 5)
BPE는 문자 단위에서 빈도 수가 많은 쌍(pair)을 찾아 점차적으로 단어 집합을 만들어가는 방식을 취한다. Wordpiece는 Bert에서 활용된 서브 워드 토크나이즈 알고리즘이며 BPE의 변형 알고리즘이다.
Wordpiece는 모든 단어의 앞에 _를 붙이는데 이는 decode를 위한 것으로 복원할 때 현재 있는 모든 띄어쓰기를 전부 제거하고, 언더바(_)를 띄어쓰기로 바꾼다.
SentencePiece
구글은 Bert에 wordpiece를 사용했지만 구현체를 공개하지 않아 대부분의 한국어NLP 개발자들은 SentencePiece를 사용한다. 구글은 센텐스피스라는 BPE와 기타 서브 워드 토크나이징을 포함한 알고리즘을 발표한다.
SentencePiece는 단어 분리 알고리즘을 사용하기위해서 사전 토큰화 작업없이 전처리를하지않은 raw 데이터에 바로 단어 토크나이저를 사용할 수 있다는 이점을 제공한다.
Kobert로 네이버 영화평 한 문장을 토크나이즈 하면 아래 그림 5와 같이 나타난다.

네이버 영화평 코퍼스 로드
아래와 같이 git clone을 통해 네이버 영화평 코퍼스를 가져온다.

설치된 nsmc 밑에 있는 ratings_train.txt(훈련데이터세트 15만건), ratings_test.txt(테스트세트, 5만건)을 pandas 테이블 형식으로 로드한다.

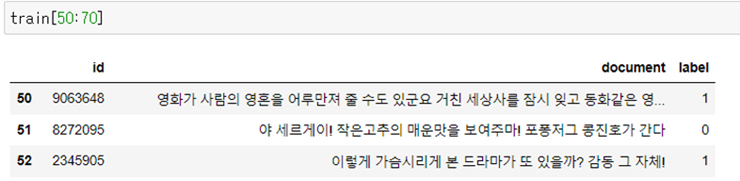
Train에 로드된 데이터를 확인해본다. id, document, label의 테이블 형식으로 로드 되어있다.
지난 글에 이어 감성분석 처리절차와 Bert 언어모델, Kobert, 네이버 영화펑 코퍼스 로드까지 살펴보았다. 다음 글에서는 KonertTokenizer 환경 준비부터 훈련 및 평가까지 알아보고자 한다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카
관련기사
- 딥러닝(DL)을 통한 한글 문장의 감성분석은 어떻게 이뤄지나 ①
- 퓨리오사AI 1세대 실리콘 ‘워보이(WarBoy)’, 카카오엔터에 도입
- 우리은행, LG AI연구원과 초거대 AI 상용화 추진
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
- 한컴, 그룹웨어 챗봇에 ‘엑소브레인’ 기술 적용
- GCP, 카카오브레인에 클라우드 TPU 공급…AI 언어모델 개발 지원
- 인공지능(AI)을 활용한 객체탐지(Object Detection)는 어떻게 작동하나 ①
- 에이프리카, 서울바이오허브에 인공지능(AI) 개발 인프라 구축
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?