![[source=damo academy]](https://cdn.itbiznews.com/news/photo/202102/29603_26141_152.jpg)
만약 스마트폰에서 찍은 사진을 웹사이트에 전송하면 고양이인지 아닌지를 머신러닝(ML)으로 판별해주는 프로젝트를 시작한다고 하자.
훈련 및 테스트 데이터는 웹사이트의 고양이 사진을 사용한다고 할 때, 실제 프로젝트의 성능은 기대에 못 미칠 확률이 높다. 사용자의 스마트폰에서 업로드 되는 사진은 웹사이트의 고양이 사진에 비해 조명이나 선명도, 해상도 등이 다르다.
이 경우에 성능을 높인다고 웹사이트의 고양이 사진을 다운로드 받아 만든 훈련 세트를 늘리면 성능은 높아질까?
데이터, 모델의 크기와 성능과의 상관관계
일반적으로 심층신경망의 규모를 늘리거나, 데이터를 늘리는 방법이 알고리즘의 성능을 높이는 보다 신뢰할 수 있는 방법으로 거론되고 있다. 그러나 위와 같은 실제 프로젝트에서는 고려해야 할 사항이 좀 더 복잡하다.
이 경우, 훈련 데이터와 다르게 개발/테스트 세트 데이터로 분리하고 가능하면 동일한 분포 데이터에서 개발 및 테스트 세트를 취득하고, 이와 더불어 단일 측정 지표를 가지는 등의 일이 필요하다. 예를 들어 정확도 혹은 F1 score 같은 하나의 지표 말이다.
이 것을 가지고 분류기 A와 분류기 B의 개발 세트에서의 지표를 비교하며 경우의 수를 판별해야 0.1%의 성능 향상이 어디에서 언제 일어났는지 혹은 개발 테스트 세트에서 과대적합(overfitting) 이 일어났는지 등의 평가를 할 수 있다. 이와 더불어 주기적으로 테스트 세트 평가를 같이 병행하는 것이 필요하다.
만약 알고리즘의 성능이 훈련 세트 오류 1%(99% 정확도), 개발 세트 오류 11%(89% 정확도)라고 하자. 이 경우 편향(bias)은 1% 그리고 편차(variance)는 10%( = 11% - 1%) 이다. 즉 편향은 훈련 세트 알고리즘의 오류율이다.
이는 분류기가 훈련 세트에서는 매우 작은 오류를 갖지만, 개발 세트에 적용하기에는 오류가 높은 것이다. 즉 범용적으로 일반화 하기에는 부적합한 상태, 우리는 이것을 과대적합(ovefitting)이라고 부른다.
또 다른 예를 살펴보자. 만약 알고리즘의 성능이 훈련 세트 오류 15%(85% 정확도), 개발 세트 오류 16%(84% 정확도)라고 하자. 이 경우 앞에서 배운 바와 같이 편향(bias)는 15% 그리고 편차(variance)는 1%(= 16% - 15%)이다.
이 경우 분류기가 훈련 세트에는 15% 오류로 썩 좋지 않은 성능이고 개발 세트에서의 오류율은 훈련 세트 오류율보다 약간 높다. 이 분류기는 높은 편향과 낮은 편차 이다. 우리는 이 알고리즘이 과소적합(underfitting) 되었다고 한다.
이론적으로는, 편차(variance)는 대용량의 훈련 세트를 훈련함으로써 줄일 수 있다. 그리고 편향(bias)은 심층신경망의 층(layer)과 뉴론(unit)을 증가시키는 것과 같은 모델의 크기 증가를 통해 줄일 수 있다.
그러나 이는 또한 편차를 증가시켜 과대적합의 위험을 불러온다. 이런 경우, 잘 설계된 정규화(regularization) 방식을 사용하여 과대적합 문제를 피해가는 방법을 모색한다.
홈그라운드와 호주 원정 경기
지금까지 살펴본 내용을 국가 대항 양궁 시합에 비유해 본다면 이럴 것 같다. 양궁 선수들이 실내체육관의 환경에서 과녁에 명중시키는 훈련을 10,000번의 활시위를 당겨 거의 과녁의 중심에 맞추게 되었다면 이는 국내 훈련 환경에 과대적합 되었다고 말할 수 있다.
원정 경기에서는 일정한 방향으로 바람이 불어 한국에서는 정가운데 명중하던 활시위가 호주 원정 경기장에서는 과녁의 우상향에 일정하게 몰려 있다면 이는 피할 수 없는 편향이라고 볼 수 있다.
원정 경기장의 소음에 놀라 표적 위아래로 산발적으로 펼쳐서 활시위가 퍼져 있다면 이는 국내 연습 대비 편차이다.
원정 경기의 상태가 바람이 심하게 불고 소음도 무척 심한 상태인 것에 대비해서 국내에서 훈련하면서 바람이 불어 대며 소음이 있는 환경을 만들어 훈련에 대비했다면 이는 테스트 세트 평가를 같이 병행하여 데이터 변화에 대비했다고도 볼 수 있다.
비유가 적절했는지 모르지만, 불특정 다수의 사용자로부터 이미지 입력을 받는 것과 같은 상태의 프로젝트에서는 머신러닝 알고리즘이 훈련한 데이터와 개발 및 테스트로 나뉜 데이터의 이질성을 염두에 두는 것과 같이 성능 최적화는 여러 변수를 염두에 두고 전략을 생각해 볼 필요가 있다는 점이다.
텐서보드
통상 모델을 개발하고 훈련 중간에 정확도와 손실률들을 출력하여 학습의 진행과정을 모니터하거나, matplot 시각화도구등을 통해서 정확도와 손실률을 훈련이 끝나고 난 후에 시각화하여 보곤 한다.
모델을 이해하고 디버깅 및 최적화를 돕기 위해 시각화도구인 텐서보드(Tensorboard)가 제공됨을 알고 있을 것이다. Pytorch를 사용하시는 분들은 Torch.utils.tensorboard 라이브러리를 사용하여 텐서보드를 사용할 수 있다.
주위에 보면 텐서보드를 잘 쓰는 이도 있지만 노트북 프로그램안에 몇가지 추가하는 내용이 불편해서인지 사용하지 않는 분들도 많은 것 같다.
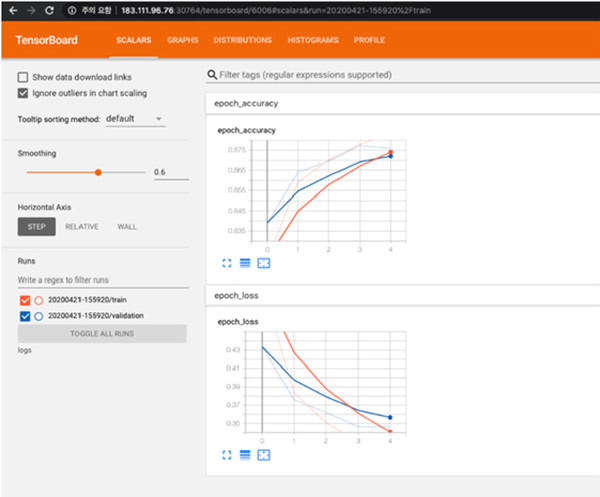
만약 훈련 손실률과 정확도 그리고 개발용 손실률과 정확도를 비교한다면 텐서보드가 무척 깔끔하게 처리된 시각화 화면을 제공한다. 즉 여러 시도들을 비교하여 epoch 증가에 따른 변화를 관측하기에 편리하다.
예를 들어, 텐서플로우 2.0 버전이 지원되는 이미지/커널환경에서는 엔쓰리엔클라우드의 Cheetah Notebook Extension 을 이용하여 별도의 어려운 처리 과정없이 쥬피터 노트북내에서 바로 임포트하여 사용할 수 있다.
텐서보드를 시작하기 위하여 쥬피터 노트북이나 랩에서 Cheetah Notebook Extension을 로드하고,

만약 Keras를 사용하는 프로그램의 경우 model compile 다음에 로그 지정 디렉토리와 tensorboard_callback을 지정하고,

model.fit 에서 callbacks=[tesorboard_callback]) 을 정의한다.

그리고 아래와 같이 tensorboard 를 실행하면,

화면에 텐서보드가 실행되는 구조다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 엔쓰리엔클라우드
관련기사
- 2021년 전자설계·테스팅 시장에서 예상되는 기술 트렌드와 변화상 ②
- MS애저 기반 DW 솔루션 공개한 MS, “혁신사례로 기업 DT 돕겠다”
- 주니퍼, 의도기반 네트워킹(IBN) 기업 앱스트라 인수
- NXP반도체, 이기종 차량용 컴퓨팅 개발 플랫폼 ‘블루박스’ 버전 업데이트
- 차세대 반도체, 양자컴퓨팅, 클라우드네이티브…올해 주목해야 할 IT산업 키워드
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”
- 확산되고 있는 클라우드 환경과 인공지능(AI) 개발 플랫폼의 부상
- “파괴적 혁신이 주목받는 시대, 인공지능(AI) 뉴노멀 시대로의 전환은 스타트업에게 기회”
- “AI개발자들, 주목!”…복수의 GPU를 활용한 분산 훈련 최적화 방법론
- 엔쓰리엔클라우드, 인천스타트업파크 빅데이터·AI플랫폼 구축 완료