![[source=pexels]](https://cdn.itbiznews.com/news/photo/202103/31429_27893_5219.jpg)
“4개의 GPU로 분산 훈련(Distributed Training)을 시행하면, 1개의 GPU로 훈련하는 것보다 4배로 성능이 빨라질까?”
결론부터 이야기하면 4배로 빨라진다. 물론 복수 기계 간의 네트워크 속도나 어떤 병렬 학습 전략을 채택하느냐에 따라 차이가 있으나 자체 테스트 결과 GPU 증가에 따라 이미지 분류의 경우 선형적으로 초당 이미지 처리 성능이 증가했다. 이 설명은 뒷부분에서 다루겠다.
처음 머신러닝(ML) 모델을 만들고 학습용 데이터로 하나의 서버에서 훈련을 실행할 경우에는 별다른 속도의 병목현상을 느끼지 못할 수도 있지만, 딥러닝(DL)의 특성상 데이터와 모델이 커지면 피할 수 없이 직면하는 문제는 훈련 시간의 증가다.
만약 단일 서버에 4개의 GPU가 있다면, 4개 모두 GPU를 대상으로 병렬 훈련을 실행하면 그렇다. 훈련에 4시간이 소요되던 것이 1시간에 끝난다.
만약 3대의 서버에 각각 4개의 GPU가 장착되어 있다면, 이 모두를 연결하여 12개의 GPU에 분산 훈련을 시행할 수 있다. 각각의 경우에 적용할 수 있는 병렬 학습 전략을 고려해야 한다.
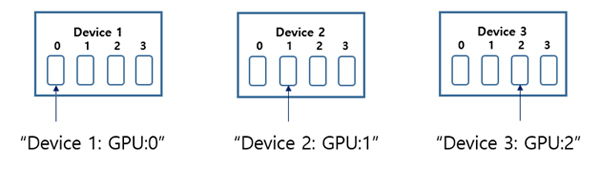
훈련의 과정은 대다수 아다시피 먼저 모델이 학습데이터를 읽어서 ▲초기화한 weight와 모델이 feed forward 를 통해 예측한 값, ▲예측 값과 실제 값의 차이로 나타나는 손실 함수, ▲손실을 weight로 편미분한 경사도(gradient)를 구하는 과정 등이 반복되면서 결국 weight가 변경되는 과정이다.
분산 훈련은 각 GPU 당 1개의 작업 프로세스(worker process)가 위치하여 각 GPU의 경사도 값을 서로 주고 받고 각자의 worker는 모아진 경사도(gradients)들의 평균을 이용하여 모델을 변경한다.
이처럼 worker는 한 번의 반복마다 경사도를 모두 모아서 변경하므로 모든 worker는 언제나 같은 파라미터(weight)를 갖는다. 이를 동기(synchronous) 방식이라고 하며 비동기 방식도 있으나 설명은 생략한다.
MultiWorkerMirroredStrategy도 있는데 이는 복수의 노드(서버)에 장착된 GPU를 대상으로 한다. 기본적으로 동기 방식의 MirroredStrategy와 같은 방식이다.
다만 복수의 노드에 소속된 GPU에 데이터가 배치되고 각 GPU worker에서 훈련된 경사도(gradient)로부터 계산된weight가 all-reduce 방식으로 전체 GPU가 모두 같은 weight를 갖도록 실행되는 점이 다르다.
텐서플로우로 분산 훈련하기
텐서플로우 가이드에 명시된 분산 훈련 부분에는 tf.distributed.Strategy를 tf.keras나 tf.estimato 와 함께 사용할 수 있다고 설명하고 있다. 아울러 지원하는 5가지 분산 훈련 전략도 아래와 같이 설명하고 있다.

TF2.0 베타 버전에서는 케라스와 함께 Mirrored Strategy를 사용할 수 있고 CentralStoreStrategy 와 MultiWorkerMIrroedStrategy는 아직 실험 기능이므로 추후 바뀔 수 있다고 나와있다.
동일 서버 내 복수의 GPU를 통한 분산 훈련
이 경우는 텐서플로우의 동기화방식인 MirroredStrategy를 사용하기위해 케라스의 경우 몇 줄의 코드를 기존 머신러닝 코드 위에 추가하면 된다.
예를 들면, 모델과 옵티마이저를 만들기 전에 with mirrored_strategy.scope()를 정의한다든지, 혹은 입력데이터를 각 GPU worker에 배분하는 부분과 경사도 계산을 위한 정의 등이다. 케라스를 사용한 MNIST 사용 예는 텐서플로우 사이트 내 케라스를 사용한 분산 훈련 튜토리얼을 참고하면 된다.
복수 서버 내의 복수의 GPU를 통한 분산 훈련
앞에 살펴본 텐서플로우 분산 훈련 tf.distributed.Strategy의 경우 텐서플로우 가이드에 따르면 TF2.0 베타버전에서 현재 API를 개선하고 있다. 케라스와 함께 MirroredStrategy만 지원하고 있는 상태다.
복수의 기계에 장착된 복수의 GPU를 통한 분산 훈련을 시행하기 위해서 호로보드(Horovod) 방식을 적용해보았다.
호로보드는 우버(Uber)에서 분산 훈련으로 MPI 모델과 ring-allreduce worker 간 경사도 교환 방식을 사용한 복수 GPU를 장착한 복수 서버 간의 분산 훈련에 탁월하다.
호로보드를 통한 복수 서버 내의 복수의 GPU 분산 훈련
호로보드는 리눅스재단 산하의 LF AI 재단이 주최하는 머신러닝 표준으로 특히 우버 내부에서는 MPI 모델이 훨씬 간단하고 텐서플로우보다 분산 훈련을 위해 휠씬 적은 코드 변경이 필요하고 속도도 빨라서 호로보드 방식을 사용한다고 한다.
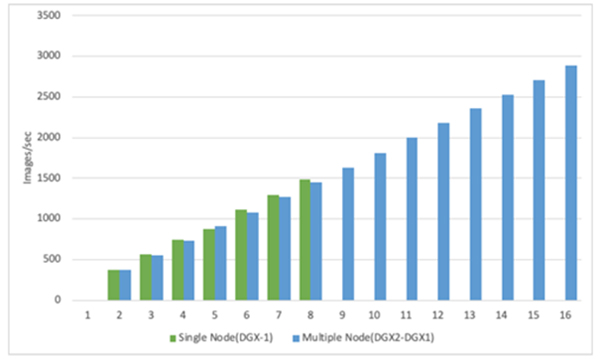
엔쓰리엔클라우드가 엔비디아의 고성능 AI연구용 HPC인 DGX-1(V100 8개 GPU), DGX-2(V100 16 개 GPU)를 대상으로 tf_cnn_benchmark 수행 시 이미지 처리량을 비교한 결과, 아래와 같이 GPU 노드가 증가함에 따라 이미지 처리 성능도 일정하게 증가하는 결과를 확인하였다.
아울러 Infinity band 100GPS에서 복수의 노드(서버) 테스트 수행 시, 단일 노드(서버) 수행보다 단지 1.3% 감소한 이미지 처리량을 보였다.
호로보드를 통하여 복수 서버상의 복수 GPU 대상으로 분산 훈련을 하기 위해서는 기존 프로그램에 import horovod.tensorflow as hvd를 포함한 7~8라인 정도의 프로그램의 코드 추가가 필요하다.
AI플랫폼 치타에서의 분산 훈련
치타(CHEETAH)에서 분산 훈련을 사용하기 위해서는 우선 프로젝트관리에서 작업추가를 선택한 후에 분산 트레이닝 타입 선택을 통해 단일노드내의 분산 GPU(Distributed GPU)를 사용할지, 혹은 복수 노드의 분산 GPU(Horovod)를 사용할 지를 선택한다.
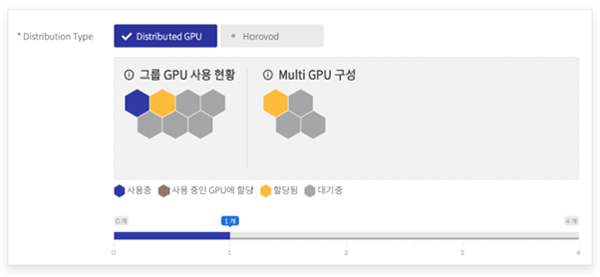
당연한 얘기지만 Distributed GPU를 선택하면 단일 노드에서 사용할 수 있는 최대 GPU 개수까지 할당할 수 있다. 만약 Horovod를 선택했다면, 복수 노드에서 사용할 수 있는 최대 GPU 개수까지 할당할 수 있다.
이 경우 팀들이 그룹별로 GPU를 공유하고 있는 상태에서 한 사용자가 복수 노드의 전체 GPU를 점유하여 분산 훈련을 하려는 시도일 수도 있어 프로젝트 관리의 스케쥴링 관리로 진입하여 잡스케쥴링을 등록하게 한다.

이를 통해 전체 관련 팀원들이 언제 얼마만큼의 GPU 작업이 예약되어 있는지 알수 있다. 이러한 잡스케쥴링 기능이 분산 훈련이 잘 끝났는지 여부도 모니터링할 수 있도록 설계되어 있다.
단일 서버의 GPU 분산 훈련은 현재 시점에서 텐서플로우의 케라스 API를 통해 분산 훈련이 가능하며 기존 프로그램에 3~4라인의 프로그램을 추가하면 된다. 이 상태에서 치타의 Distributed GPU의 작업관리에서 테스트 버튼을 누르는 것으로 아주 쉽게 실행을 할 수 있다.
복수 서버의 GPU 분산 훈련은 호로보드를 선택하고 위와 같은 경로로 실행하면 된다. 기본 프로그램에 6라인 정도의 호로보드를 위한 코드 추가만 하면 된다. 나머지는 치타가 알아서 분산 훈련을 처리해 준다.
초보자도 사용설명서를 보고 기존 프로그램에 이러한 코드를 추가하고 치타의 자동 분산 훈련 수행 기능을 사용해보자. 어렵게 느껴졌던 복수 서버의 분산 훈련을 몸소 체험해볼 수 있는 기회다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 엔쓰리엔클라우드
관련기사
- 향후 5년간 수요증가 예상되는 디지털 기술은 ‘AI/ML’
- 인공지능(AI), 데이터가 늘어나면 성능도 최적화될까?
- 베스핀글로벌, 공유 스타트업 ‘올롤로’ 빅데이터 플랫폼 구축 프로젝트 완료
- 삼정KPMG, “은행업계는 생존 위해 디지털 비즈니스, DT 도입해야”
- 오브젝트스토리지·계층화…올해 스토리지 시장에서 주목해야할 키워드
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”
- 아이크래프트·엔쓰리엔클라우드, 인공지능(AI) 사업 확장 ‘맞손’
- 확산되고 있는 클라우드 환경과 인공지능(AI) 개발 플랫폼의 부상
- “파괴적 혁신이 주목받는 시대, 인공지능(AI) 뉴노멀 시대로의 전환은 스타트업에게 기회”
- 고사목 현황 조사에 AI 활용…정확도 ‘높이고’ 조사기간 ‘단축하고’