![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202109/48251_43653_4613.jpg)
안면확인 vs 안면인식
안면확인(face verification)은 안면 영상과 해당 사람의 이름이나 ID 등을 입력했을 때, 데이터베이스로부터 해당 ID나 이름을 찾아서 입력된 영상이 저장된 영상과 맞는 지를 확인하는 시스템이다. 즉 입력 이름과 ID에 해당하는 영상이 맞는지를 매칭하는 1:1 시스템이다.
반면 안면인식(face recognition)은 다수(N개)의 안면 이미지가 데이터베이스에 저장되어있으면서 안면 이미지가 입력되면 그 저장 되어있는 다수의 안면 이미지 중 하나에 해당하는 지를 인식하는 시스템으로 N:1 의 경우의 수로 비교를 수행한다.
One Shot Learning
안면인식은 입력된 영상 하나만을 기준으로 판별을 해야 한다는 점에서 ‘One Shot Learning’의 예이다.
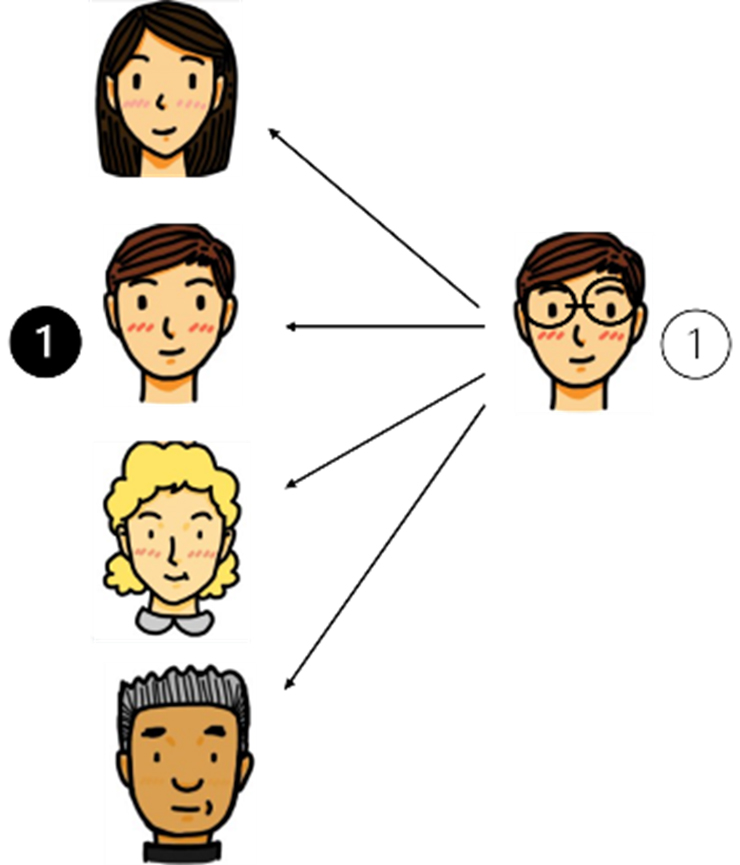
즉, 아래 그림 1과 같이, 출입구의 카메라에 얼굴을 비추면, 입력된 얼굴 ①을 보고 기존 데이터베이스에 저장된 얼굴 이미지 중에 있는 ❶을 맞춰야 하는, 즉 하나 혹은 매우 작은 수의 훈련 샘플/이미지로부터 정보를 학습해야 하는 객체 분류인 One Shot Learning의 예인 것이다.
이것은 영상 분류에 있어서 수백, 수천 이상의 훈련 샘플/이미지와 매우 큰 데이터셋이 필요하다는 일반 인식에 역행한다. 역사적으로 딥러닝(DL)은 하나의 입력 데이터를 가지고 훈련을 해야하는 One Shot Learning에 매우 취약한 것이 사실이다.
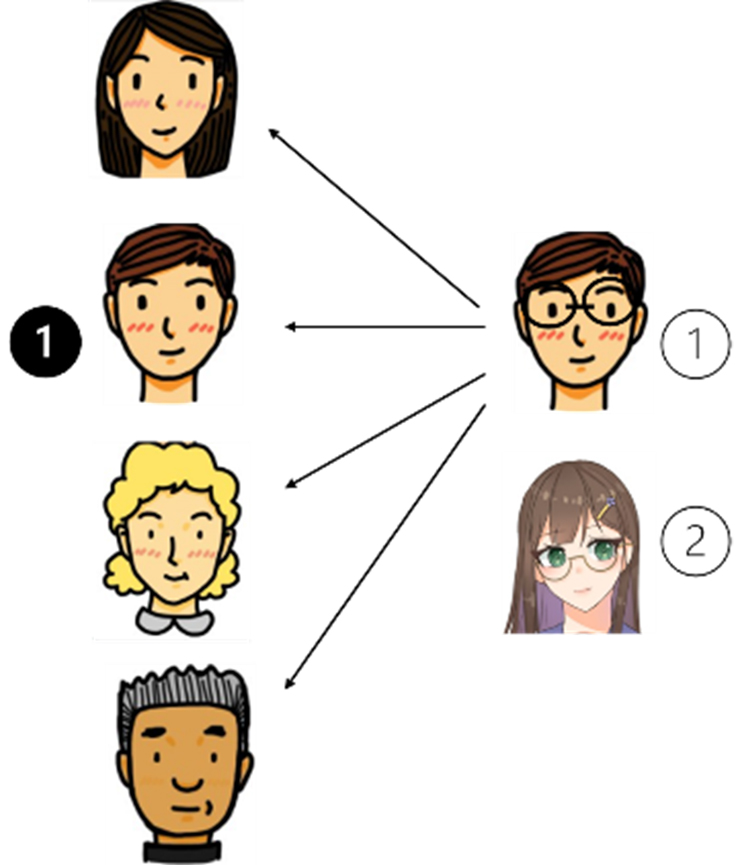
자 이제 4명의 직원을 대상으로 훈련을 마친 상태에서 만약 아래 그림 2와 같이 새로운 직원 ②가 입사하면 어떻게 될까?
이제 직원이 5명이 되었고 그러면 5명을 대상으로 훈련을 다시 해야 할까? 만약 직원이 1000명이고 매달 10명씩 새롭게 직원이 늘거나 퇴사한다면? 인원 변동이 있을 때마다 컨볼루션 심층 신경망을 통한 훈련을 매번 다시 해야 한다는 말일까? 이런 방식의 문제 접근법은 그리 좋은 방법이 아닌 것 같다.
유사도 함수(similarity function) 학습
이 문제를 해결하기 위해 위의 그림 2의 ①과 ❶을 이미지 벡터의 유사도를 측정하는 방법으로 접근한다. 만약 ①과 ❶의 이미지의 차이가 허용 값 안에 들어온다면 우리는 두 이미지는 ‘같다’고 판정한다.
가령 허용 값을 0.3 이내라고 정하였다면, ①과 ❶의 비교는 0.1 그리고 왼쪽의 나머지 3명의 값은 이 값보다 모두 크다면 당연히 ①과 ❶은 같은 사람이라고 판단하는 것이다. ①은 ❶의 사람이 안경을 쓴 이미지로 이미지 벡터의 유사도가 ‘같다’는 범위로 나타날 것이다.
자 그럼 새롭게 입사한 ②의 경우는? 마찬가지로 ②의 이미지가 데이터베이스에 저장만 되면, 새로운 직원 ②의 입력이 들어왔을 때, 바로 전에 ①과 ❶의 수순을 똑같이 거치면서 두 이미지 사이의 유사도를 측정하여 판별할 것이다. 별도로 전체 데이터베이스에 있는 이미지들의 훈련이 필요 없이 말이다.
자 그러면 이렇게 ①과 ❶처럼 두 개의 이미지를 입력 받아 유사도를 비교하는 함수는 어떻게 만들어지는 것일까?
샴 신경망 네트워크(Siamese Neural Network)
샴 쌍둥이라는 말을 들어본 적이 있을 것이다. 이와 같이 샴(영어 발음은 사이어미스) 신경망 네트워크는 두 개의 서로 다른 입력 이미지를 같은 네트워크 구조와 같은 파라미터(weight)를 공유하며 사용하여 출력되는 각각의 최종 벡터를 비교 연산하기위해 쓰이는 심층신경망을 뜻한다.
그림 3과 같이 두 사람의 안면 이미지를 입력으로 하여 convolution, pooling, fully connected layer를 거쳐 128바이트의 feature 벡터를 출력으로 만들어 냄으로써 샴 네트워크 구성을 완성한다.
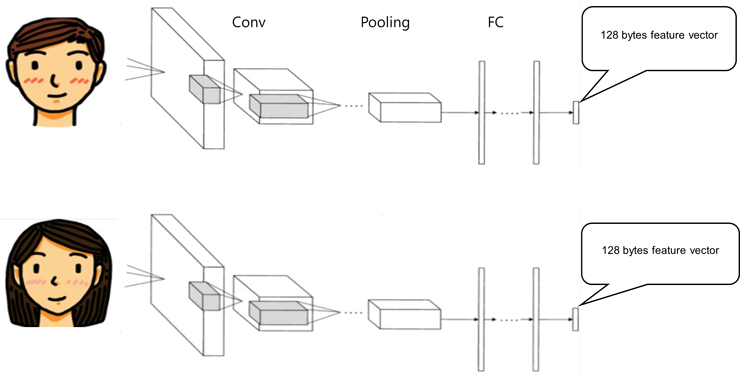
두 네트워크는 파라미터 및 네트워크 구조가 동일하기 때문에 최종 출력으로 나온 예를 들어, 128바이트 크기의 feature 벡터라고 하면, 이 벡터 숫자들의 유사도를 측정함으로써 앞에서 살펴본 것과 같이 두 입력 이미지의 유사도가 어떠한지 비교할 수 있게 된다.
입력된 두 개의 안면영상 이미지가 다르기 때문에 네트워크와 파라미터가 동일하게 구성되었지만, 128바이트 크기로 출력되는 feature 벡터 숫자들도 허용치 이상으로 다르게 나올 것이다.
즉, 이 두 128바이트 크기의 벡터 간에 유클리드 공간에서의 거리를 측정하여 떨어진 거리가 허용치 안에 들어오느냐 여부를 가지고 유사도를 측정할 것이다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카(구 엔쓰리엔클라우드)
관련기사
- 자일링스, 모토비스와 전방 카메라 인식기술(OD) 고도화
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?
- 스마트폰에서 심층강화학습 인공지능(AI) 구동된다
- ST마이크로, 센서퓨전 테크기업 아이리스와 협력 강화
- 순차 입력 정보를 처리하는 심층신경망(DNN) 구조…어떻게 작용할까?
- 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ①
- “머신러닝(ML) 개발 중 모델 모니터링과 딥러닝(DL) 모델을 동시 개선하는 방법”
- 맥심, 신경망 MCU에 아이집 DL모델 적용…에너지 효율성 개선
- “훈련이 끝난 머신러닝(ML) 모델, 어떻게 서비스 할 수 있을까?”
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”