![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202105/36631_32504_657.jpg)
“컴퓨터가 문장에 있는 단어의 품사를 어떻게 알아낼까?”
우선 주어진 문장에서 Part of Speech라는 문장 속 단어의 품사를 판별한다.
만약 웹사이트에 있는 문장들이건 혹은 챗봇을 통해 입력된 문장이 되었건, 의미 있는 문맥으로 구성된 문장들을 컴퓨터가 자연어처리를 하려고 할 경우에, 문장을 이해하기 위해 가장 기본적으로 수행되어야 하는 기능 중 하나가 ‘Part of Speech(POS) tagging’이라고 하는 품사를 판별하는 일을 한다.
Part of Speech는 품사에 근거하여 단어가 문장의 어떤 부분에 있는 지를 파악하여 코퍼스(말뭉치)를 검색할 때나 혹은 같은 단어라도 쓰임새에 따라 명사 혹은 동사가 되는 경우에 단어의 출현을 구별 지을 때에도 사용된다.
파이썬 언어의 라이브러리는 문장의 토큰을 분리하는 기능과 문장에 있는 단어의 품사를 표시하는 기능을 라이브러리로 제공한다.
파이썬의 NLTK 라이브러리는 문장 토큰을 만드는 것과 POS 꼬리표(tagging)를 붙이는 기능을 기본적으로 제공한다. 파이썬의 .split() 기능도 있지만 NLTK의 word_tokenize 는 보다 견고한 토큰을 생성한다. 아래 예를 보자.
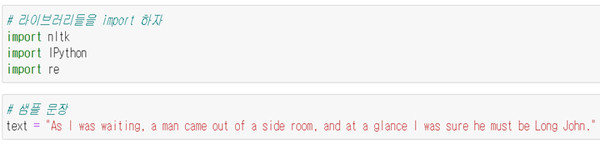
라이브러리들을 import 하고 샘플 문장을 text에 담았다. 우선 POS 꼬리표를 만들기 전에 전처리(preprocessing)과정을 통하여 소문자로 전부 전환하고, 글의 여러 가지 경계를 구분하기 위해 사용되는 반점(,), 물음표(?), 쌍반점(;), 붙임표(-) 등의 구두점들을 제거한 후 문장을 토큰으로 분할한다.

이 과정을 통하여 문장 중의 대문자가 소문자로 치환된다, 예를 들어 [As I was waiting]은 [as i was waiting]으로 바뀐다. 문장 분석에서 대문자는 큰 의미가 없어 전부 소문자로 바꾼다.
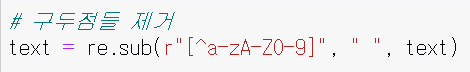
이 과정을 통하여 문장 중에 a-zA-Z0-9 즉, 소문자, 대문자, 숫자를 제외한 구두점들은 “ “ 즉 빈칸으로 치환된다. 즉, 이 과정은 구두점들이 있는 문자들을 빈칸으로 없애는 전처리 작업이다.
우리가 관심을 같는 것은 단어이기에, 나머지 부호는 무시하는 것이다. 여기서 re.sub 표현은 파이썬 언어의 re라는 라이브러리를 처음에 import 한 것을 알 수 있다.
import re를 통하여 re 라이브러리가 이 프로그램으로 불려왔고 re.sub라는 형식을 통해 r” 로 표시되는 부분 이후가 ,“ “ 즉, 콤마 이후의 빈칸으로 대치(substitute) 된다.

text = text.split()을 통하여 문장 [As I was waiting, a man came out of a side room, and at a glance I was sure he must be Long John.]이 ‘as’, ‘i’, ‘was’, ‘waiting’,….’john’와 같이 토큰으로 분할 된 결과를 볼 수 있다. 분할된 as, i, 와 같은 개체가 토큰이다.
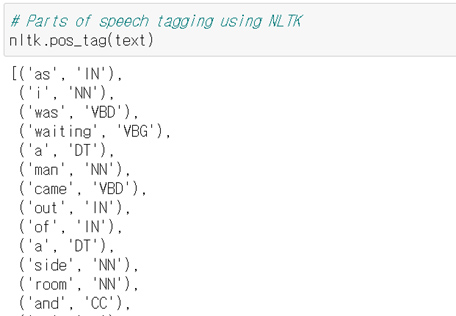
분할된 토큰들이 text에 담겨있는데 이를 nltk.pos_tag(text) 와 같이 파이썬 nltk 라이브러리의 pos_tag라는 함수에 넣으면 그 아래 표시되는 것처럼, as는 IN과 같이 꼬리표(tagging)가 붙는다.
NLTK가 부여하는 POS 꼬리표의 예는 다음과 같다.

Bigram참조 테이블 작성
지금까지 문장 단어의 품사를 확인했다면 그 다음으로 주어진 단어 다음에 올 단어를 예측하기 위해 bigram이라는 것을 사용해보자. 연속된 단어들이 주어졌을 때 그 다음에 올 단어를 예측하는 것은 자연어처리에서 ngram이라는 방식으로 일컬으며, 여기서 n=2 일 때 bigram이라고 한다.
무슨 얘기인가 하면, 문장 중에 연속하는 단어 두 개씩을 계속 비교하면서 문자열 중에 출현 분포를 분석하는 것이다. 아래의 예를 보자.
관련되는 라이브러리들을 import 한다.

만약 text = [“Mary saw Jane”, “Jane saw Will”] 이라는 문장이 있을 경우, preprocess 라는 함수를 통해 소문자변환, 구두점 제거, 토큰화 이후에 Tokens에는 Text에 있던 문장이 토큰으로 분할되었고, Labels에는 해당되는 품사가 분할되어 있음을 볼 수 있다.
이제 nltk.bigram 함수를 통하여 Token 과 Labels 의 bigram 을 생성한다.

화면에 출력된 Tokens bigram 쌍들을 N-M, M-V, V-N 등의 품사 전이 컬럼과 아래와 같이 매칭해본다. 여기서 N은 Noun(명사), M은 Modal(can-will 과 같은 조동사), V는 Verb(동사)이다.

위의 테이블과 아래 샘플 문장을 비교해보면 will-see로 이어지는 쌍은 3번 출현함을 알 수 있다.
여기까지 주어진 문장의 텍스트들을 품사 판별을 위한 전처리과정으로서 소문자 변환, 구두점들 제거, 토큰으로 분할한 후에 nltk 라이브러리의 nltk.pos_tag(text)함수를 통하여 토큰과 쌍을 이루는 POS tagging 이 만들어지는 것을 살펴보았다.
그 다음 2개의 토큰 윈도우를 대상으로 품사 전이 상태와 bigram 간의 참조 테이블을 작성해 보았다. 이 참조 테이블은 각각의 bigram 들이, 품사가 명사에서 조동사로 그리고 조동사에서 동사 등으로 이전하는 상태에 대해 관측되는 확률을 표시한 것으로 볼 수 있다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 엔쓰리엔클라우드
관련기사
- “머신러닝(ML) 개발 중 모델 모니터링과 딥러닝(DL) 모델을 동시 개선하는 방법”
- “훈련이 끝난 머신러닝(ML) 모델, 어떻게 서비스 할 수 있을까?”
- 엔쓰리엔클라우드, 인천스타트업파크 빅데이터·AI플랫폼 구축 완료
- “AI개발자들, 주목!”…복수의 GPU를 활용한 분산 훈련 최적화 방법론
- 인공지능(AI), 데이터가 늘어나면 성능도 최적화될까?
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”
- “파괴적 혁신이 주목받는 시대, 인공지능(AI) 뉴노멀 시대로의 전환은 스타트업에게 기회”
- 네이버·서울대, 한국어 기반 ‘초대규모 AI’ 고도화 맞손…공동 연구센터 설립
- 오타도 알아서 수정·검색…네이버, ‘초거대 AI언어모델’ 검색 서비스에 반영
- “전세계 기업 38%, 코로나19 확산 기간에 업무자동화 툴 사용 늘렸다”