![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202104/33278_29461_2020.jpg)
생각해보자. 데이터 수집과 전처리도 어렵게 끝나고 훈련, 검증, 테스트 세트의 데이터를 대상으로 훈련 및 테스트가 끝났다. 축하한다.
그러나 연구용이나 실험용으로 모델을 한번 만들어 본 것이 아니고 머신러닝(ML)을 실제 현장에서 사용자에게 서비스할 계획이라면 모델 서비스라는 쉽지 않은 과정이 남아있다.
머신러닝 파이프라인이란 머신러닝을 통해 데이터수집부터 모델 훈련, 모델 서비스, 성능 모니터링까지의 반복적 사이클을 진행하는 것을 말한다.
이번 글에서는 머신러닝 플랫폼 '치타(CHEETAH)'를 사용하여 실제 훈련된 머신러닝 모델을 대외적으로 실제 환경에서 사용자들에게 서비스하기 위해 준비해야 하는 과정을 살펴보기로 하자.
머신러닝 모델 개발은 사용자 서비스를 위한 것
연구에 의하면 머신러닝 모델은 전체 파이프라인 과정의 5%밖에 차지하지 않는다고 한다. 훈련이 20%를 차지하고 아마 상당부분 기간이 소요되는 영역이 데이터 수집 및 정제, 그리고 모델 서비스 부분이 아닐까 싶다. 아래 그림1은 파이프라인 순서도이다.

모델 서비스(model deployment)는 모델 훈련이 끝난 머신러닝 모델을 실제 서비스 환경에서 의사결정에 사용될 수 있도록 배치하는 것이다.
가령 아래 그림2와 같이 머신러닝에서 자주 사용되는 MNIST 데이터 학습, 즉 손글씨 0에서 9까지의 28X28 픽셀의 이미지들을 분류하는 모델을 대상으로 한다면, 외부(스마트폰)에서 아래와 같이 8이라는 손글씨 이미지가 머신러닝이 학습된 서버(클라우드)로 HTTP를 통해 보내지면 서버의 훈련된 모델이 분류를 수행한 후 ‘8’이라는 결과를 다시 스마트폰으로 보내주는 것이다.
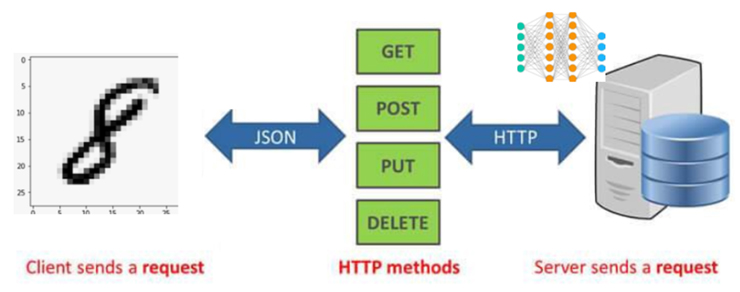
치타에서는 몇 줄의 코드 추가와 클릭을 통하면 HTTP 및 gRPC 모델 서빙이 가능하다. 이러한 모델 서비스가 가능하려면 치타에서의 다음과 같은 절차가 필요하다
1. 우선 서버(클라우드)에 있는 MNIST 분류 머신러닝 모델이 아래와 같은 코드가 모델을 서비스하도록 추가되어 훈련이 끝나 있어야 한다. 자세한 사항은 텐서플로우 서빙 모델 편을 참고하기 바란다.

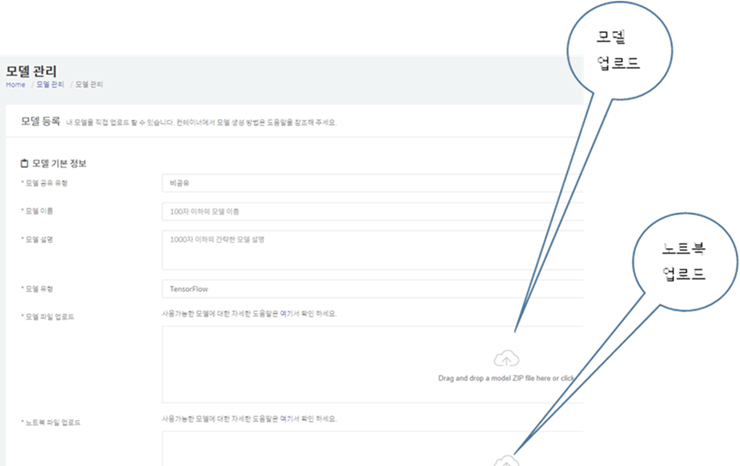
2. 치타 플랫폼의 모델관리로 들어가서 모델업로드 버튼을 누르면 아래 그림3과 같은 모델업로드 화면이 나오고 위 1번에서 서버에 저장된 모델을 끌어다가 모델업로드에 넣는다.(위와 같은 코드가 들어간 모델 훈련이 끝나면 export_path에 정의한 장소에 모델이 저장된다)
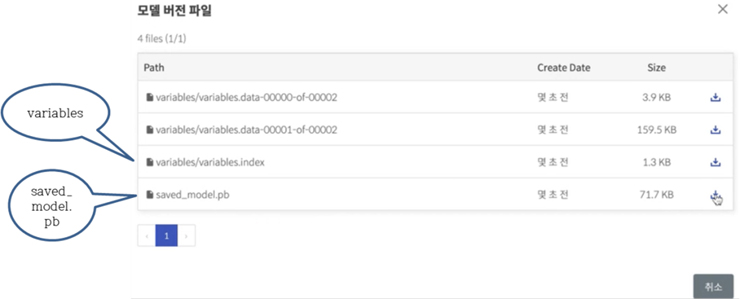
3. 다시 모델관리로 돌아가서 버전정보 ‘보기’를 누르면 아래 그림4와 같이 서빙될 모델의 버전을 확인할 수 있다. 여기서 saved_model.pb는 직렬화된 텐서플로우의 저장된 모델로 그래프정의와 시그니처와 같은 모델의 메타데이타가 저장된 것이다.
variables는 그래프의 직렬화된 변수를 보유하는 파일이다. 이들을 확인함으로써 모델이 서빙될 준비가 되었음을 확인해보자.
4. 치타의 모델배포관리 화면으로 들어가서 등록을 누르고 배포할 모델을 선택한 후 모델배포 파라미터에서 instance 유형을 스마트폰에서 제공될 mnist 이미지로 등록하고 저장을 누른다.
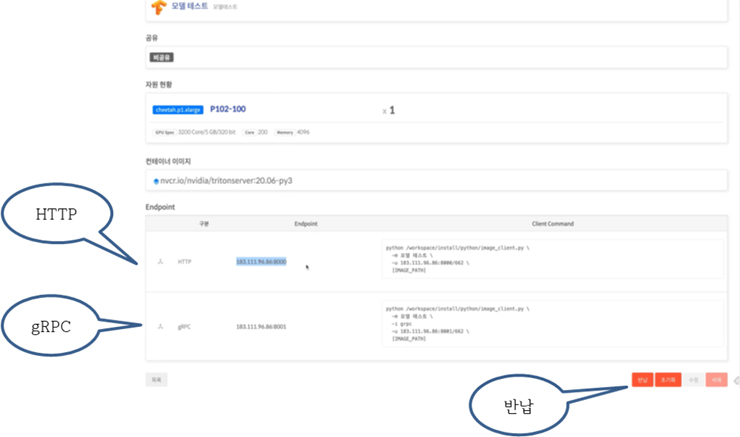
5. 그러면 아래 그림5와 같은 모델배포 테스트화면이 나타나고 하단의 생성 버튼을 누르면 배포 테스트를 수행할 수 있는 환경이 좌측 상단에 ‘생성중’으로 나타난다. 그림5에서 보듯이 서비스하는 대상에 따라 HTTP 와 gRPC 통신 프로토콜을 선택할 수 있다.
HTTP는 동기방식의 RestAPI를, gRPC는 구글에서 개발한 오픈소스 RPC(원격절차호출) 프레임워크다. 마이크로서비스아키텍쳐 환경에서 다양한 서비스들이 상호간에 통신이 빈번한 상황에서 JSON을 통한 직렬화는 취약함에 기인하여 개발한 통신 프레임워크다.
특히 이미지처리등의 서비스에서 벤치마트 성능은 gRPC가 HTTP 대비 5배 이상의 성능을 나타내는 것으로 되어있다.
6. 모델배포 테스트 상단좌측 화면에 ‘생성중’이 ‘서비스중’으로 바뀜에 따라 이제 모델을 대외적으로 서비스할 준비가 되었다.
7. 이제 스마트폰에서 28X28 픽셀 규격의 손글씨 이미지를 RestAPI 혹은 gRPC 프로토콜로 머신러닝 서버 측에 분류 추론을 의뢰하는 송신 프로그램을 작성해서 보내면 서버(클라우드)의 모델이 분류한 후 결과를 스마트폰으로 ‘8’이라고 보내주는 과정의 서비스가 진행된다.
현장 데이터를 통한 모델 서빙 품질 개선
머신러닝 파이프라인에서 모델 배포 다음으로는 모델 평가가 필요하다. 모델 평가는 기존의 생성된 모델을 새로운 입력 데이터로 테스트하는 과정이다.
지금 서버나 클라우드에 훈련이 끝나 서비스 되는 모델은 주어진 데이터를 훈련용과 테스트용으로 나누어 훈련한 것의 정확도와 응답속도를 가지고 있다.
스마트폰에서 입력되는 손글씨 이미지도 서버에서 훈련할 때 보여줬던 정확도와 응답속도를 계속 보여줄까?
아마 그렇지 않을 확률이 높다. 일단 스마트폰으로 촬영한 손글씨 이미지는 이미지 조도와 잡음 등으로 인해 독립된 환경에서 데이터가 확보되고 훈련된 MNIST 데이터보다 예측하기 어려운 결과를 보여줄 수 있다.
예를 들어 피부에 돌출한 종기를 촬영하여 피부암을 판별하는 모델에 전송할 때도 마찬가지다. 스마트폰의 픽셀 크기와 조도, 잡음 등으로 새로운 입력 데이터가 일관된 응답속도와 정확도를 내는지 새로운 현장 데이터로 성능이 만족될 때까지 체크하는 과정이 필요하다.
머신러닝 파이프라인중에 수행하기에 난이도가 높은 모델서빙 부분은 치타가 제공하는 모델배포 자동화 기능으로 손쉽게 서비스가 가능하다.
치타 플랫폼은 복수의 호스트에 돌아가는 마이크로서비스 환경에서 안정적이고 일관성 있는 성능 제공을 위해 컨테이너, GPU, 로드밸런스등의 관리가 쿠버네티스와 함께 서비스메쉬를 담당하는 istio 플랫폼과 엔비디아의 tritron inference server로 보장된다. 텐서RT, 텐서플로우, Pytorch 와 ONNX 서빙을 손쉽게 제공할 수 있도록 제공된다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 엔쓰리엔클라우드
관련기사
- 엔쓰리엔클라우드, 인천스타트업파크 빅데이터·AI플랫폼 구축 완료
- “AI개발자들, 주목!”…복수의 GPU를 활용한 분산 훈련 최적화 방법론
- 유니티, AI/ML 적용한 로보틱스 학습 툴 데모 공개
- ETRI, 코로나 영향에도 표준화 성과…지난해 국제표준특허 72건 확보
- 인공지능(AI), 데이터가 늘어나면 성능도 최적화될까?
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”
- 아이크래프트·엔쓰리엔클라우드, 인공지능(AI) 사업 확장 ‘맞손’
- “파괴적 혁신이 주목받는 시대, 인공지능(AI) 뉴노멀 시대로의 전환은 스타트업에게 기회”
- 엔쓰리엔클라우드, AI 개발 플랫폼 ‘치타(CHEETAH)’ 기능 고도화 작업 완료
- 스트라드비젼, ‘GTC 2021’서 OD 툴킷 ‘SV넷(SVNet)’ 기능 업데이트 발표