![[사진=게티이미지]](https://cdn.itbiznews.com/news/photo/202303/93907_89683_1014.jpg)
지난 글에서는 손실 함수와 유사도 함수, mask를 통한 labels 그리고 similarity matrix 생성 등에 대해 알아봤다. 이번 글에서는 logits과 labels 생성, 훈련 및 평가에 대해 알아본다.
이전 기고문 확인하기
☞ 라벨 데이터가 적은 상황에서 딥러닝(DL) 영상분류 성능 개선법 ①
☞ 라벨 데이터가 적은 상황에서 딥러닝(DL) 영상분류 성능 개선법 ②
우선, Pytorch의 CrossEntropyLoss에서 target을 index로 출력하는 예를 살펴보자.
criterion = nn.CrossEntropyLoss(),
loss = criterion(input, target)
이때 input에 해당하는 것이 logits, target에 해당하는 것이 labels이다. 그림 10에서 positives와 negatives의 횡적 결합한 8 X 7 행렬이 logits이고, labels는 positives 샘플들의 인덱스를 포함한 1 X 8 행렬로써, labels는 CrossEntropy를 각 행의 logits를 보고 0값의 벡터를 보고 positive 쌍이 첫번째 인덱스에 있음을 알려주는 indicator function으로 일반적으로 사용하는 라벨과는 다른 내용이다.
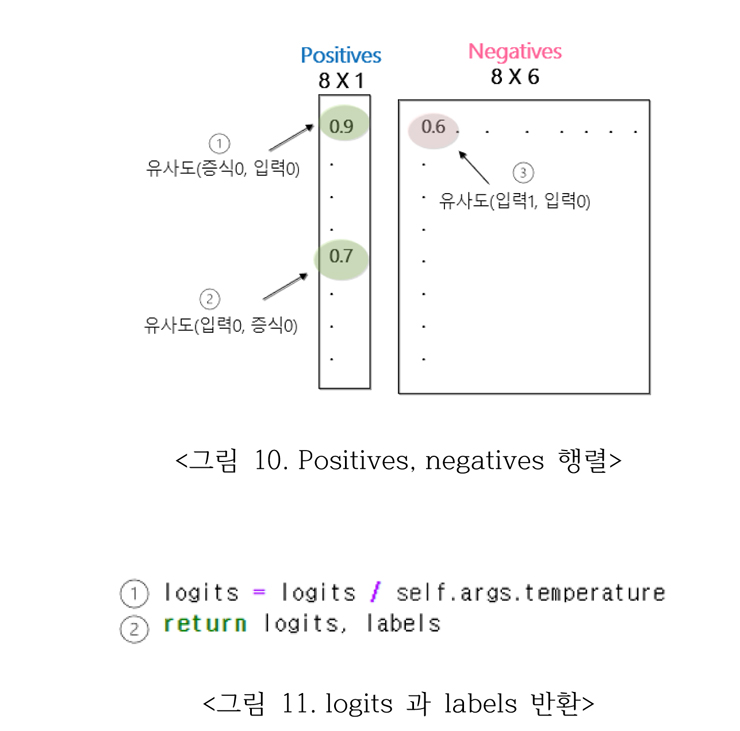
그림 11의 ①을 통해 대조 학습을 위한 온도 계수를 logits에 적용하는 부분이다. 1편의 그림 1에서 Ʈ는 출력 카테고리 간의 구분을 명확 혹은 부드럽게 출력하는 온도 계수라고 설명하였다. ②에서 logits 와 labels를 리턴 한다.
지금까지 살펴본 info_nce_loss 함수는 simclr.py의 train 함수에서 사용한다.
logits, labels = self.info_nce_loss(features)
loss = self.critetion(logits, labels)
유사 이미지 representation끼리 유사도가 높게, 다른 이미지 representation끼리는 유사도가 낮게 만들어 주기 위해 info NCR loss를 계산하여 최소화한다. positive pair는 자기 자신(주어진 anchor image)와 증식 이미지이다.
이때 원본 이미지끼리, 증식 이미지끼리의 유사도는 loss 계산 시 배제한다(그림 8의 labels[~mask]에서 대각선 1이 제거 됨으로써). 결국 자기 자신(주어진 anchor 이미지)와 다른 이미지의 유사도를 일일이 계산하기보다 자기 자신과 증식된 이미지만을 positive sample로 선택함으로써 손실 함수처리가 된다.
◆훈련
대조 학습으로 훈련을 시행하기위해 아래와 같은 명령을 수행한다. datasets 디렉토리가 필요하고 그 밑에 stl10_binary가 생기는데 아래와 같은 명령어에 맞게 stl10 디렉토리와 symbolic link로 맞추어 주던지 하는 것이 필요하다.
python run.py -data ./datasets -dataset-name stl10 --log-every-n-steps 100 --epochs 100
100 epoch 훈련이 끝나면 runs 밑에 일자_job_xx 디렉토리가 생기고 그 밑에 아래 그림 12와 같은 파일들이 생성된다. 훈련 환경은 엔비디아 2080Ti GPU 4대로 ubuntu20.04, Pytorch 1.10, Pthon3.8, CUDA11.3이며 시간은 4시간 29분이 소요되었다.
◆성능 평가
훈련을 통해 만들어진 분류기의 정확도를 측정하기위해 학습한 encoder를 고정(freeze)하고 그 위에 linear classifier를 추가하여 정확도를 측정한다. 코드는 feature_eval 디렉토리 밑에 mini_batch_logistic_regression_evaluator.ipynb 노트북 코드다.
우선 아래와 같이 stl10 ResNet-18 공식 데이터세트를 ①과 같이 download=True로 하여 다운로드 받는다.
앞에 훈련에서 사용했던 데이터세트를 사용해도 되지만, 사전 학습 모델을 이용하여 모델이나 데이터세트의 차이에 따른 정확도 측정을 위해 주어진 mini_batch_~ 코드를 최대한 활용해본다. 그림 12와 같은 내용이 ./data 디렉토리 밑에 다운로드 된다.

아래와 같이 다운로드 된 디렉토리에서 config.yml을 로드 한다. ①은 현재 torch 1.10, cuda 11.3, python 3.8 환경에서 yaml.load 에서 error가 발생해서 unsafe_load로 변경하였다.

사전 훈련 모델은 아래와 같이 resnet18 모델을 정의한다. ①번과 같이 선언함으로써 weight를 불러오지 않는다. 우리는 저장된 체크포인트를 로드해서 사용할 것이다.

그림 13의 ①번과 같이 저장되었던 체크포인트 파일을 로드하고, ②번과 같이 모델 state_dict의 backbone.으로 시작하는 접두사를 제거함으로써 fc.wieght와 fc.bias를 제거한다. 하지만 model.named_parameters()에는 fc.weight와 fc.bias 이름과 구조는 보존하고 있다.

그림 14의 ①번과 같이 model.named_parameters의 fc.weight, fc.bias를 제외한 나머지들을 모두 False로 선언함으로써 역전파시 gradient 연산이 일어나지 않게 된다. ②는 model.parmaters 중에 gradient enable 된 parameter를 뽑아내는 함수이다.
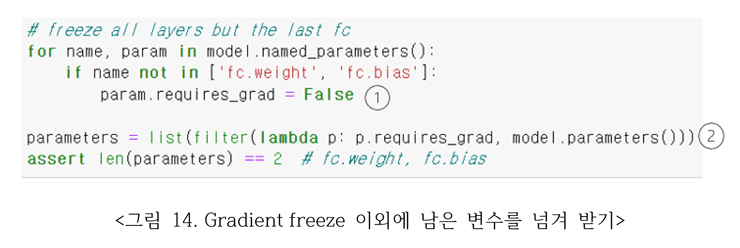
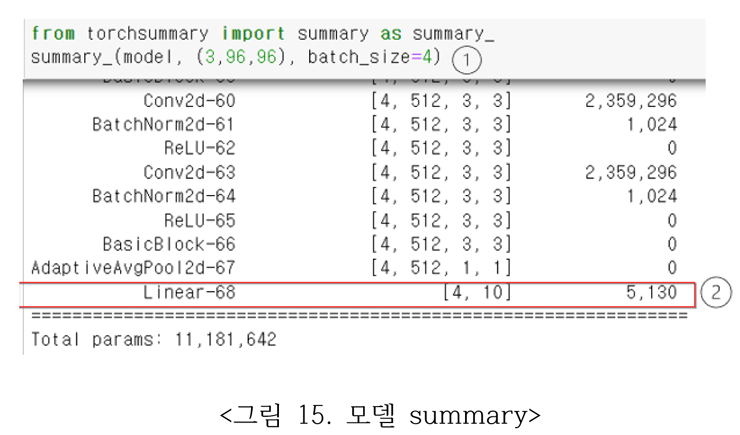
그림 15의 ①번과 같이 model의 summary를 호출하면 ②와 같이 ResNet-18의 마지막 layer에 완전연결층이 10개 class의 출력을 가지고 있음을 볼 수 있다.
◆완전연결층(FC layer) 훈련 및 모델 평가
그림 16과 같이 훈련될 gradient를 enable 한 FC를 훈련한다. epoch는 100으로 정하고 ①과 같이 모델에 x_batch를 넣어주면 logits가 출력된다. ②와 같이 logits와 y_batch와 함께 topl=(1,)를 변수로 top1 accuracy를 호출한다.
③ pytorch에서는 이후에 backward를 해줄 때 gradients 값들을 계속 더해주기 때문에 한번의 학습이 완료되면 gradients를 항상 0으로 만들어주어야 한다. ④ 오차를 역전파(backward)하기 위한 설정. ⑤옵티마이저는 parameter, learning rate 및 여러 다른 hyper-parameter를 받아 step() method를 통해 업데이트한다.

◆평가 기준 정의: top-k accuracy
먼저 top-1 accuracy를 설명해보자. 개, 고양이, 닭 등등의 서로 다른 6개의 동물들 사진이 있다고 치자. 첫 번째 분류 예측에서 6개 중에 4개를 맞추면 67% 정확도다. top-2 accuracy는 각각의 경우에 첫 번째와 두 번째 예측을 수행한 것을 모두 놓고 몇 개를 맞췄는지 평가하므로 당연히 정확도가 올라간다.
◆테스트 데이터를 통한 Top1, Top5 정확도 평가
이어서 그림 17과 같이 테스트 데이터를 로드하여 정확도 성능을 평가한다. ①은 test_loader로부터 batch 단위로 데이터를 로드 한다.
②에서 batch 단위의 테스트 데이터가 모델에 입력되어 logits를 출력. ③에서 topk=(1,5)를 변수로 logits와 y_batch를 입력하여 top1, top5 결과를 출력한다. ④를 통해 batch 단위의 결과를 평균 내어 ⑤와 같이 화면에 epoch 당 Top1 Test Accuracy와 Top 5 결과가 나타난다.

◆성능 결과
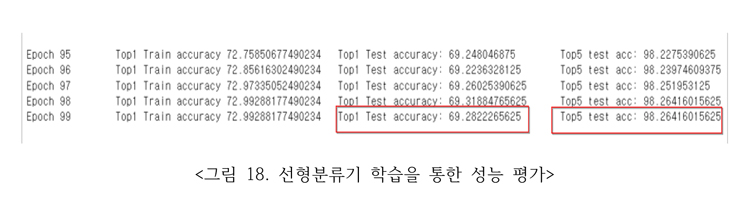
라벨 없는 10만개와 5천개의 stl10 데이터세트 훈련데이터를 입력으로 하여 대조 학습을 통한 nce loss로 100회 훈련한 사전 모델을 전이학습을 통해 로드, 성능평가를 위해 라벨이 있는 train과 test 데이터를 이용하여 마지막 FC 층만 제외한 나머지 층을 훈련을 못하도록 freeze하고 FC 층을 100회 훈련시킨 결과는 그림 18의 붉은 선에 표시된 바와 같이 Top1 정확도는 69.28, Top5 정확도는 98.26이다.
결론
이 프로젝트의 목적은 라벨 없는 영상데이터들로 이미지 분류가 가능한지와 어느 정도의 성능을 보여주는지를 살펴보는 것이었다.
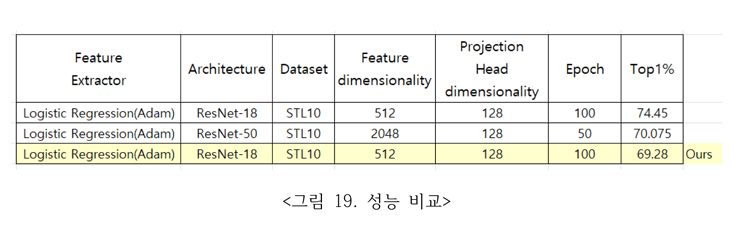
대조 학습을 위하여 라벨 없는 stl10 데이터를 훈련하였고 성능 평가를 위해 stl10 데이터의 10개 class를 보유한 train, test 라벨 있는 데이터를 마지막 층에 선형 분류기를 통하여 성능 평가를 하였다.
ResNet-50에 비하여 비교적 구조가 간단한 ResNet-18 구조를 채택하여 official record 인 74.45에는 못 미치지만 69.28 의 Top1%를 달성하였다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카
관련기사
- 라벨 데이터가 적은 상황에서 딥러닝(DL) 영상분류 성능 개선법 ②
- ‘연구개발특구 AI역량강화 지원사업’ 참여기업 모집 시작
- 딥러닝(DL)을 활용한 한국어 질의응답 예측 기술 톺아보기 ①
- 누적된 날씨 관련 시계열(Timeseries) 데이터에서 미래 기온 예측하기 ①
- 딥러닝(DL)을 통한 한글 문장의 감성분석은 어떻게 이뤄지나 ①
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
- 인공지능(AI)을 활용한 객체탐지(Object Detection)는 어떻게 작동하나 ①
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- MS·텐센트·바이두, 비전AI에 ‘엔비디아 CV-쿠다’ 채택