![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202109/49170_44576_2421.jpg)
지난 글에서는 유사도 함수 기술과 샴 신경망 네트워크에 대해 알아봤다. 이번 글에서는 유사도 함수를 학습하는 이진 분류 접근법과 현장에 적용할 때의 다양한 이점에 대해 알아본다.
이전 기고문 확인하기
☞ [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
앞의 그림 3의 최종 출력인 feature vector 128bytes를 예로 들어보자. 이 128bytes 크기로 인코딩된 벡터 간의 유클리드 공간의 거리를 비교하여 유사도를 측정하는 학습 목표를 달성하기 위하여 3중 손실(triplet loss) 함수라는 개념을 살펴보고자 한다.
아래 그림 4와 같이 우선 ①과 같이 입력이 되는 이미지인 anchor 이미지 A가 있고, 그와 비교되는 같은 이미지인 ❶의 positive 이미지 P의 한 쌍이 있다. 오른쪽은 입력이 되는 이미지인 anchor 이미지 A가 있고 그와 비교되는 다른 이미지인 ②의 negative 이미지 N이 있다.
결국 목적하고자 하는 학습 목표는 ③식에 표시된 바와 같이, A와 P 간의 거리 d(A, P)가 A 와 N 간의 거리 d(A, N) 보다 작아야 하는 것이다. 그런데 여기서 +α가 식 안에 있는 것이 눈에 띈다. +α가 있는 이유는 다음과 같다.
3중(Triplet) 손실 함수
그런데 식 ③을 가만히 보면, d(A, P) = 0, d(A, N) = 0, 결국 +α가 없다면 양쪽이 모두 0일 경우 합산이 0이 되어 식 ③을 쉽게 만족하게 된다.
우리가 원하는 것은 d(A, P)가 아주 사소한 숫자라도 간직해서 상대적으로 d(A, N)의 큰 숫자보다 월등히 비교될 수 있는 정도를 원하는 것이다. +α는 그러한 역할을 위해 마진(margin)으로 부여되는 것이다.
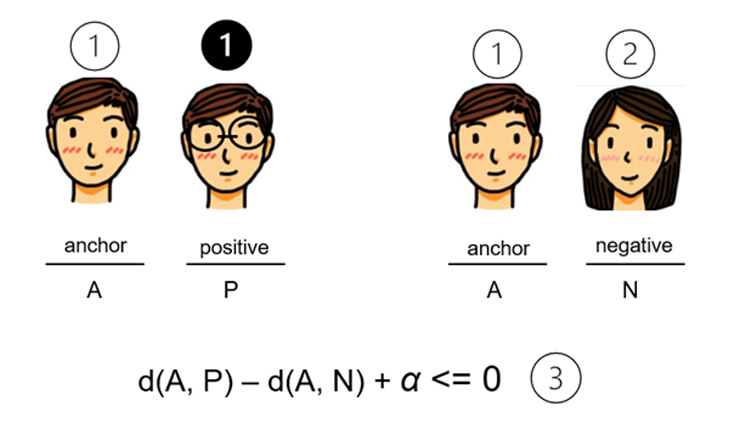
이러한 마진의 역할은 결국 d(A, P)와 d(A, N), 이 둘 간의 거리 경계를 확연히 차이가 나도록 벌려 놓은 역할을 한다는 정도로 이해하자.
아래 그림 5의 손실 함수를 살펴보자. 우리의 목표 함수는 밑줄 친 부분 ④가 0 보다 작아야 max() 값이 최소화 될 것이다.
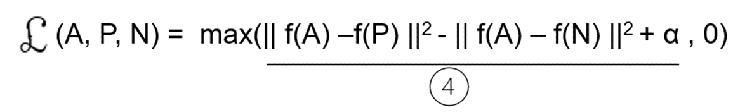
즉 max(A, 0) 형태의 손실 함수가 최소화 되려면, A값이 0보다 작을 때, 즉 아래 그림 4의 ④번 식이 0보다 작을 때, 결국 손실 0을 리턴 할 것이기 때문이다. 좌측의 그림(A, P, N)은 A 와 P 그리고 A 와 N 간의 3중(triplet) 함수임을 의미한다.
위에서 살펴본 안면 이미지 하나 당 128bytes의 feature vector를 갖는 3중 손실(triplet) 함수를 사용하여 최고 성능(state of the art)을 달성했다는 FaceNet에 대한 자세한 내용은 이 논문(링크)을 참고하자.
훈련 데이터 세트의 고려
만약 3중 손실 함수를 사용하여 훈련용 데이터를 준비한다면 사람 당 10개 정도의 서로 다른 안면 이미지(동일 사람의 서로 다른 이미지, 즉 연령대 별로 변한 이미지나, 안경을 쓴 경우, 혹은 머리 모양이 바뀐 경우 등)를 데이터베이스에 저장하는 것이 좋다.
인식하기 위한 입력 이미지(Anchor)와 동일 인물의 다른 안면 이미지(Positive)를 비교하는 훈련 d(A, P)을 위해서 한 사람 당 약 10개 정도의 서로 다른 안면 이미지가 필요하다는 얘기다.
즉 1천을 대상으로 안면 인식 시스템을 훈련시킨다면 전체 1만개의 안면 이미지가 필요하다는 뜻이다.
실제 기업에서는 몇 십만, 몇 백만 혹은 몇 천만 명의 직원들을 대상으로 안면 인식시스템을 구축하기도 한다.
이럴 경우, 미리 해당 기업이 사전 훈련(pre-trained) 시켜 놓은 모델을 가져와 전이학습으로 사용할 수도 있다. 이럴 경우에도 지금까지 살펴본 기본적인 Siamese 네트워크와 3중 손실(Triplet Loss) 함수를 이해하는 것은 도움이 될 것이다.
유사도 함수를 학습하는 이진 분류 접근법
지금까지 샴(Siamese) 네트워크의 파라미터를 공유하는 3중(triplet) 손실 방식을 살펴보았다. 아래 그림 6과 같이 샴 네트워크의 파라미터를 공유하는 방식은 동일하다.
생성된 128바이트의 임베딩된 feature 벡터 쌍을 이진 분류를 통과하여 1이면 동일, 0이면 이질 안면 이미지로 분류하는 이진 분류 문제 해결 방식으로 접근하는 또 다른 방법이 있다. 이 방식 역시 괜찮은 성능을 보여준다고 한다.
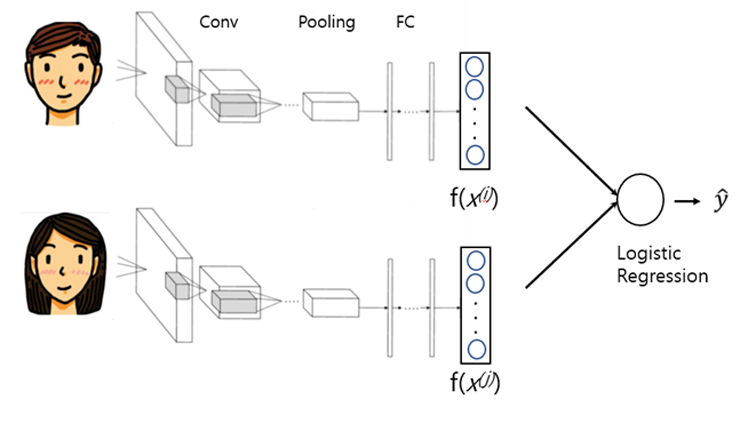
자 그러면 Logistic Regression Unit은 실제로 무슨 일을 하는 것일까? 아래 그림 7을 보면 밑줄이 그어진 ⑤번 항을 보면 결국 128바이트로 임베딩된 i와 j 두 개의 서로 다른 안면 이미지에 대해 유클리드 공간의 거리를 구하는 것이다.
앞에 붙은 k=1부터 128까지라는 수식은 결국 2개의 128바이트 임베딩 벡터를 1부터 128개 벡터 각각에 대해 두 i, j 쌍의 거리를 비교하여 그 값을 더한다는 뜻이다.
이 값이 0에 가까우면 두 이미지는 같은 인물 즉 1의 값을, 거리가 멀어지면 다른 인물 즉 0으로 이진 분류 하는 방식이다.
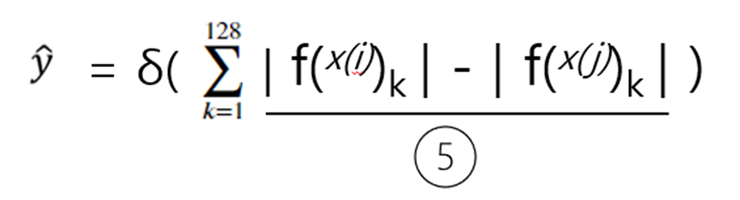
현장 적용 팁
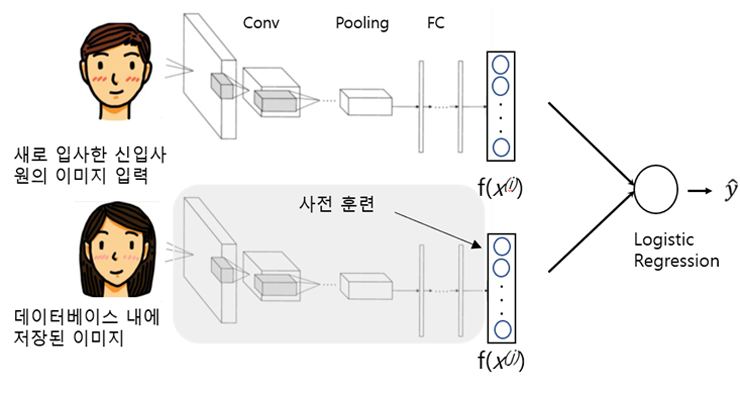
아래 그림 8처럼, 예를 들어 1만명의 직원들의 안면 이미지를 미리 샴 네트워크를 통하여 128바이트 임베딩 feature 벡터를 각각 만들어서 데이터베이스에 저장해 놓았다고 가정해보자.
아래 그림처럼 이제 새로 입사한 신입사원의 안면 인식을 훈련할 때에는, 해당 신입사원만 기존의 샴 네트워크의 파라미터와 동일하게 훈련을 진행하여 128바이트의 feature 임베딩 벡터를 생성하고, 이를 또 다른 비교 대상 이미지에게 훈련을 진행할 필요 없이 데이터베이스에 사전훈련-저장되어 있는 128바이트 임베딩 벡터만 가지고 신입사원의 128바이트 임베딩 벡터와 비교하면 되는 것이다.
이렇게 함으로써 소위 새로운 이미지 하나의 입력 샘플 만으로 유사도를 판별하는 one shot 학습이 구현되는 것이다.
이렇게 되면, 실제 모든 임직원의 안면 이미지 사진을 보유할 필요없이 사전에 연산된 임베딩 벡터들만으로 유사도 비교가 일어나므로 상당한 양의 컴퓨터 연산 부하를 줄일 수 있다.
지금까지 살펴본 바와 같이, 두 쌍의 이미지를 샴 네트워크를 이용하여 그것이 3중 손실 함수이건 혹은 이진 분류 방식이건 결국 이 두 비교 이미지 간에 훈련을 통한 임베딩 벡터의 유사도 비교를 통한 접근법으로 안면 인식을 처리할 수 있음을 살펴보았다.
2개의 컨볼루션 네트워크를 구성하고 그 둘 간의 네트워크 구조와 파라미터를 공유하며 최종적으로 출력된 임베딩된 벡터를 비교하여 유사도를 측정하는 개념은 비단 “안면인식에만 적용될까?”라는 생각이 든다.
가령, 특정 암질환에 대한 종양의 이미지를 각각 동종의 10가지 이미지를 보유한다면 새로운 종양 이미지가 입력되었을 때, 기존의 저장된 종양과 과연 같은 것이 있는 지 유사도를 탐지하는데 사용될 수 있지 않을까?
특히나 저장된 이미지 데이터베이스에 꾸준한 in, out이 있고 매번 그럴 때마다 훈련을 다시 하지 않아도 되는, one shot learning의 이러한 접근법은 딥러닝(DL)이 요구하는 대용량의 데이터 필요를 넘어 많은 응용분야에 적용될 여지가 있음을 기억하자.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카(구 엔쓰리엔클라우드)
관련기사
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?
- 순차 입력 정보를 처리하는 심층신경망(DNN) 구조…어떻게 작용할까?
- LGU+, 양자내성암호 기술 공연분야 응용서비스에 적용 확대
- 에이프리카, 멀티클라우드 플랫폼 ‘세렝게티 v2.0’ GS인증 1등급 획득
- 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ①
- 마스크 쓴 얼굴도 인식률 99%…KERI, AI 기반 안면인식 기술 개발
- 인텔, 안면인식 임베디드 솔루션 ‘리얼센스ID’ 공개
- 메타, ‘페이스북’의 안면인식 서비스 종료 발표
- 알체라, 지난해 매출액 100억 돌파…데이터사이언스 매출 성장세