![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202112/59886_54866_5856.jpg)
지난 글에 이어 이번 글에서는 개와 고양이 이미지 분류의 경우를 예로 들어 이러한 사전훈련 모델을 어떻게 사용한다는 것인지 살펴보자.
이전 기고문 확인하기
☞ “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
2,000장의 개와 고양이 이미지샘플로 시작하는 이미지 분류
우선 2013년 Kaggle 컴퓨터비전 대회에서 사용된 Dogs vs. Cats 데이터세트로부터 다운로드 받은 25,000개의 개와 고양이 사진을 다운로드 받는다.
이중 train 디렉토리 밑에 cat과 dog 밑에 해당되는 고양이와 개 이미지를 1,000개씩 할당한다. valid 디렉토리와 test 디렉토리에도 밑에 cat 과 dog 에 각각 500 개씩 이미지를 할당한다.
Keras의 image_dataset_from_directory를 이용하여 디렉토리에 있는 이미지들을 읽는다. train_dataset에 2,000개 파일이 고양이, 개의 2개 class로 구성되어 있음을 알 수 있다. valid_dataset은 1,000개 test_dataset도 1,000개를 보유함을 확인할 수 있다.
baseline모델 구축
아래 그림과 같이 Keras를 이용하여 ①텐서플로우의 분산훈련 전략인 tf.distribute.MirroedStrategy()를 통한 분산훈련 사용 ②180x180 픽셀의 3 채널(RGB) 이미지를 입력으로 정의 ③픽셀당 보유하고 있는 0~255까지의 값들을 255로 나누어 줌으로써 0~1 사이의 값들을 가지도록 rescale 해준다.
그리고 이어서 5개의 Conv2D 층과 ’relu’ activation, 그리고 MaxPooling2D가 이어지는 층이 180x180 특성맵(feature map)을 7x7까지 줄여준다. 반면 특성맵의 깊이는 32에서 256으로 는다.
④Flatten을 통하여 2차원 특성들을 일차원으로 변환시킨 후, ⑤개 혹은 고양이를 분류하는 2분법 적인 분류(binary-classification)이기 때문에 1개의 unit을 갖는 Dense 층(1개의 unit 이 0 혹은 1을 담당)에 sigmoid 활성화 함수를 쓴다.

아래 그림과 같이 training과 validation accuracy를 보면, training은 epoch가 거듭될수록 99%의 정확도로 수렴하는 한편, validation accuracy는 최고치 75%에 머무르고 있다. 이것이 정확히 training dataset에 모델이 과적합(overfitting)이 일어나고 있음을 보여준다.
Validation loss는 10 epoch 에서 최저점을 찍은 후 반등하고 반면, training loss 는 훈련이 진행됨에 따라 선형으로 감소가 일어난다.
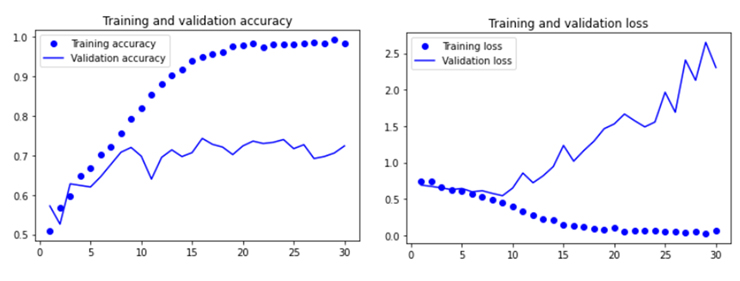
훈련에 2,000개의 비교적 작은 샘플을 사용하여 과적합이 제일 먼저 관심을 두고 지켜봐야하는 제약이다. 이러한 과적합을 피하는 기술로 dropout이나 weight dacay를 쓴다. 또 다른 방법으로 데이터규모를 늘려서 과적합을 피하는 기술이다. 바로 데이터증식 기술이다.
데이터증식(Data Augmentation)
데이터증식은 기존의 훈련 샘플들로부터 그럴듯하게 보이는 이미지들을 임의의 몇 가지 변형을 가하여 훈련 데이터를 증식하는 방법을 말한다. 이를 통하여 훈련기간 내 모델이 보다 다양한 데이터에 노출되고 과적합을 방지하는 보다 개선된 일반화에 기여한다.
아래 그림과 같이, ①RandomFlip(“horizontal”)은 입력이미지의 50%를 수평으로 뒤집는다. ②RandomRotation(0.1)은 입력이미지를 [-36도, +36도] 범위로 회전시킨다. ③RandomZoom(0.2)는 입력이미지를 [-20%, +20%] 범위 내에서 임의의 비율로 줌인 혹은 줌아웃 한다.

아래 그림은 훈련 이미지 중에 데이터 증식이후의 임의의 9개 이미지를 표시한 것이다. 좌우가 대칭을 이루기도 하고 약간 회전 된 것들도 목격되며 줌인 되고 줌아웃된 것들도 보인다.

데이터증식은 소규모 데이터샘플로부터 변형을 가했기 때문에 과적합을 완전히 제거하기에는 부족하다. 아래 그림과 같이 ①rescaling 전에 data_augmentation 정의를 포함한다.
②Dense 층 전에 Dropout을 추가하여 역부족인 과적합방지를 더욱 강화해본다. ③binary 분류여서 손실은 binary+crossentropy를, 옵티마이저는 rmsprop, metrics는 accuracy를 지정한다.

데이터증식과 dropout을 추가하였으므로 훈련중에 overfitting이 훨씬 후반부에 일어날 것을 기대하면서 epoch를 3배 늘려 100으로하여 훈련을 시킨다. 아래 그림과 같이, 데이터증식과 dropout 덕분에 과적합이 훨씬 뒤에 일어났다.
데이터증식과 dropout 이전에는 약 10epoch에서 과적합이 일어나던 것이 60~70epoch 근방에서 발생했다. Validation accuracy가 80~85% 범위에서 일관되게 움직인다. 첫 번째 시도 치고는 상당한 향상(75%->85%)이다.
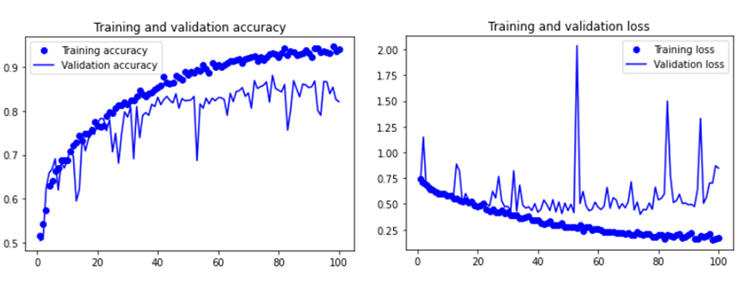
지금까지 Kaggle의 Dogs vs Cats 데이터세트로부터 4,000개의 이미지 샘플을 가지고 텐서플로우 Keras 라이브러리를 이용하여 처음부터 일반화 없이 baseline 모델을 구축하여 75%의 validation_accuracy를 확인하였고 데이터증식과 dropout 등을 통해 80~85% 로 향상되는 것을 확인하였다.
소규모 데이터로 딥러닝 이미지 분류의 정확도를 향상시키기 위한 다음 단계는, 앞에서 언급한 사전 훈련된 모델을 사용해야만 한다. 다음 편에서는 이 부분에 대해서 다룰 것이다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카(구 엔쓰리엔클라우드)
관련기사
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
- 엔비디아 잡겠다…英 팹리스 그래프코어, IPU-팟(POD) 앞세워 도전장
- ETRI, ICCV ‘자율주행용 객체분할·추적기술’ 대회서 1위
- 네이버·카카오, 국제 컴퓨터비전 학회(ICCV)서 AI기술력 입증
- 인공지능(AI)을 활용한 객체탐지(Object Detection)는 어떻게 작동하나 ①
- 퓨리오사AI, ML퍼프(ML-Perf) AI추론 벤치마크서 엔비디아 눌렀다
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?
- 순차 입력 정보를 처리하는 심층신경망(DNN) 구조…어떻게 작용할까?
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ③