![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202201/60438_55402_1659.jpg)
사전훈련 모델 이용
사전훈련 모델이란 ImageNet과 같은 대용량 데이터세트의 이미지 분류 작업을 사전에 훈련시켜 놓은 모델을 말한다. 물론, 누군가가 이미 훈련을 시킨 가중치를 사용함으로써 소규모 데이터세트로도 좋은 성능을 낼 수 있다.
이전 기고문 확인하기
☞ “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
☞ “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ②
예를 들어, ImageNet 은 이미지들이 동물들이나 우리가 일상에서 볼 수 있는 자전거, 가구, 자동차 같은 1천가지 종류 class로 구성된 140만개의 레이블 된 이미지들을 가지고 있는데, 여기에서 훈련된 모델을 목적을 달리해 가구 이미지를 분류하는 데 사용할 수 있다는 뜻이다.
만약 사전훈련에 사용된 데이터가 상당히 크고 일반적인 이미지들이라면(반드시 사전훈련 데이터 규모가 충분히 커야 한다.
반대로 사전훈련 모델의 훈련된 데이터세트가 작고 이를 다른 목적에 사용하는 모델의 데이터세트가 크다면 전이학습은 시도할 의미가 없다), 새로운 목적으로 구축할 모델 데이터 class가 사전훈련된 것과 다르다 하더라도 유용하게 이미지 분류 문제를 해결할 수 있다는 뜻이다.
앞서 1편과 2편에서 설명한 합성곱(convolutional) 신경망의 특징의 하나인 사전학습된 모델에서 학습된 패턴의 공간 계층성(spatial hierarchy)이 영상인식의 일반화된 모델로서 효과적으로 작용한다.
ImageNet이 개와 고양이 등을 포함한 여러 동물 class들을 포함하고 있는 것을 고려할 때, 개와 고양이 분류 문제에서 잘 동작할 것이라는 기대를 해볼 수 있다.
전이학습 절차
사전 학습된 모델을 통한 전이 학습을 고려할 때 아래와 같은 절차를 염두에 두는 것이 필요하다.
1. 사전 훈련 모델 선정: 우선 당면하고 있는 문제에 적당한 사전 훈련 모델을 선별하는 것이 필요하다. Keras의 경우 VGG, Resnet, Inception, Mobilenet 등의 모델들을 사용할 수 있다. 여기를 눌러 Keras에서 가능한 모델들을 살펴본다.
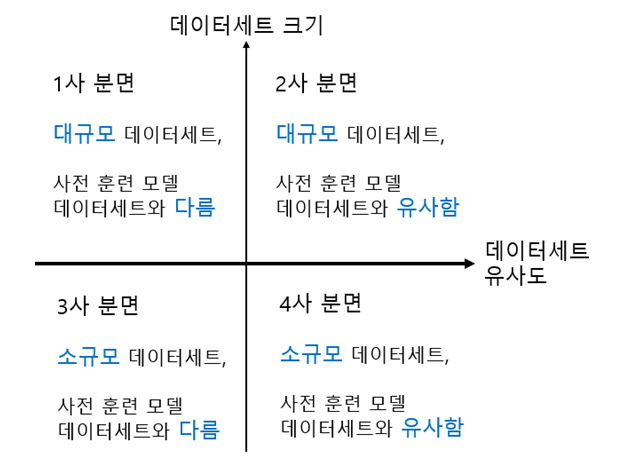
2. 데이터세트 크기와 유사도에 따른 전략 수립: 아래 그림1과 같이 데이터세트 크기와 유사도에 따라 4개의 전략이 가능하다. Class 당 약 1천~2천개의 이미지샘플은 소규모 데이터세트 크기에 속한다.
개와 고양이를 분류하는 것이라면 ImageNet의 데이터세트와 유사한 데이터세트로 볼 수 있다. 만약 현미경 데이터나 암세포 이미지를 분류하는 경우에는 ImageNet 과 유사한 데이터세트로 보기 어렵다.
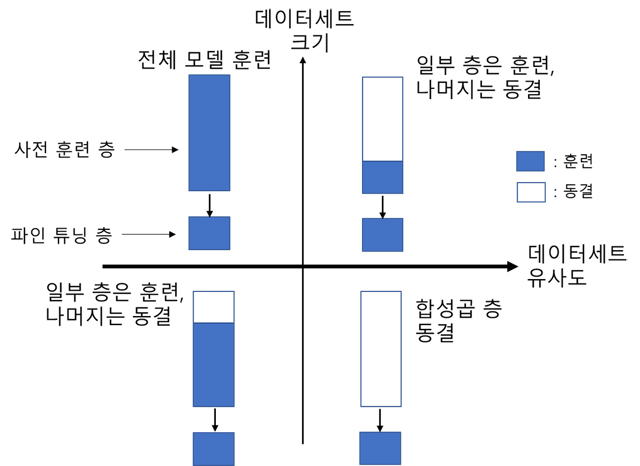
3. 모델 파인 튜닝: 크기와 유사도에 따른 전략에 따라 어느 분면에 해당하는지에 따라, 아래 그림 2와 같은 파인 튜닝 접근법을 택할 수 있다.
- 대규모 데이터, 사전훈련 데이터와 다름: 대규모 데이터를 보유하고 있다면 처음부터 전체를 합성곱 신경망에 훈련할 수 있다. 사전훈련 모델 데이터세트와 다르지만, 사전훈련 모델을 활용하는 것이 유용하다.
- 대규모 데이터, 사전훈련 데이터와 유사함: 대규모 데이터라 과적합 이슈는 없다. 데이터세트가 유사하므로 사전 훈련된 가중치를 이용하여 합성곱 층의 상층부 일부와 classifier 부분을 훈련시킨다.
- 소규모 데이터, 사전훈련 데이터와 다름: 가장 곤란한 경우다. 합성곱의 훈련 층을 늘리면 과적합이 일어나고 훈련 층을 줄이면 학습이 불충분 해진다. 2사분면의 경우보다 합성곱 층의 훈련을 늘리고 데이터증식(Data Augmentation)을 고려해보는 것이 필요하다.
- 소규모 데이터, 사전훈련 데이터와 유사함: 사전학습 모델의 가중치를 그대로 사용하고(훈련을 freeze하고) 마지막 완전연결층의 훈련된 classifier를 제거하고 대신 새로운 classifier로 교체한다.
사전훈련 모델 선정
앞에서 살펴본 바와 같이, 개와 고양이 이미지를 약 2천개의 이미지샘플을 활용해 딥러닝(DL)으로 시도하려는 경우는 그림1의 4사분면에 해당한다.
Class 당 약 1천~2천개의 이미지샘플은 소규모에 해당하고, 개와 고양이를 분류하는 것이라면 ImageNet의 데이터세트는 유사한 데이터세트로 볼 수 있다.
사전훈련 모델로는 2014년 ImageNet 데이터세트를 기반으로 개발된 VGG16 구조를 선정한다. 비교적 오래된 구조지만 모델 크기도 크지 않고 새로운 구조적 발전에 대한 설명 없이도 단순해서 이해가 용이하다.
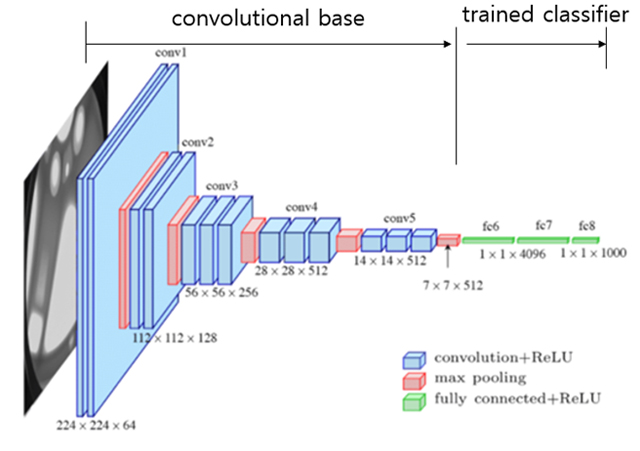
이러한 이유에서 ResNet, Inception, Xception 등이 있지만 교육용으로 많이 소개된다. 그림3과 같이, VGG16는 5개의 합성곱(Conv) 신경망과 5개의 max pooling, 그리고 3개의 fully connected layer로 이루어져 있고 모든 활성화함수는 ReLU를 사용한다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카
관련기사
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ②
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ①
- 인공지능(AI)을 활용한 객체탐지(Object Detection)는 어떻게 작동하나 ①
- 에이프리카, 서울바이오허브에 인공지능(AI) 개발 인프라 구축
- [그것을 알려주마] 안면인식 시스템은 어떻게 작동하는 걸까? ①
- 넷플릭스, 왓챠…OTT플랫폼의 추천시스템은 어떻게 동작할까?
- 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ②
- KAIST 정기훈·이도헌 교수팀, 3D 표정인식용 AI 라이트필드 카메라 개발
- “데이터가 부족해요”…딥러닝(DL) 통한 이미지 분류할 때 고려할 점 ④