![[사진=게티이미지뱅크]](https://cdn.itbiznews.com/news/photo/202106/39353_35023_2545.jpg)
이전 글에서는 컴퓨터가 자연어처리를 하는데 있어 품사를 어떻게 부여하는지에 대한 기초적 단계를 살펴보고 품사 전이 상태와 bigram 간의 참조 테이블을 설명했다.
이전 기고문 확인하기
☞ 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ①
만약 조동사(Modal)나 동사(Verb)가 더 늘어나면, 즉 단어가 더 늘어나면 품사(POS)를 어떻게 예측할 수 있을까? 이번 글에서는 문장 내 단어가 늘어날 경우의 품사를 결정하는 구조에 대해 알아본다.
문장의 품사 부여는 단어들 주위의 문맥들로부터 단어의 구문 범주를 결정하는 프로세스다. 이는 높은 정확도로 빠르게 수행 되어야함으로 자연어 구문의 차이를 구별하도록 도움을 주는데 주로 사용된다.
마르코프체인
아래의 그림은 품사전이의 변화를 마르코프 체인으로 표시해본 것이다. Markov model은 어떠한 날씨, 주식가격 등과 같은 어떠한 현상의 변화를 확률 모델로 표현한 것이다.
![[그림 1. 품사전이 및 품사별 단어 출현 빈도에 대한 마르코프모델]](https://cdn.itbiznews.com/news/photo/202106/39353_35024_2631.jpg)
Hidden Markov model(HMM)은 이러한 Markov model에 은닉된 state와 직접적으로 확인 가능한 observation을 추가하여 확장한 것이다. HMM은 observation을 이용하여 간접적으로 은닉된 state를 추론하기 위한 문제를 풀기 위해 사용된다.
가령, 아래 표와 같이 명사, 조동사, 동사별로 문장 속의 각 단어들이 각각 언급되는 빈도를 가지고 있다고 가정해보자. 즉 명사(N) 컬럼을 보면 Mary는 전체 9번의 언급된 명사 범주중에, 4번 나타나고 있음을 알 수 있다.
즉 아래와 같이 우리가 관측(observation)한 품사별 언급이 있고, 이를 이용하여 간접적으로 은닉(hidden)된 상태 즉, 입력된 문장에 대해 최적화된 품사 구성을 추론하는 문제로 Hidden Markov Model을 통해 답을 구할 수 있다.
표출확률
우선 아래와 같이 관련 라이브러리들을 import 한다. 파이썬의 확률모델 중 hidden markov model을 손쉽게 다룰 수 있는 pomegranate를 사용한다.
![[그림 2. 표출 확률(emission probabilities) 테이블]](https://cdn.itbiznews.com/news/photo/202106/39353_35025_2723.jpg)
설치는 pip install pomegranate 로 된다.
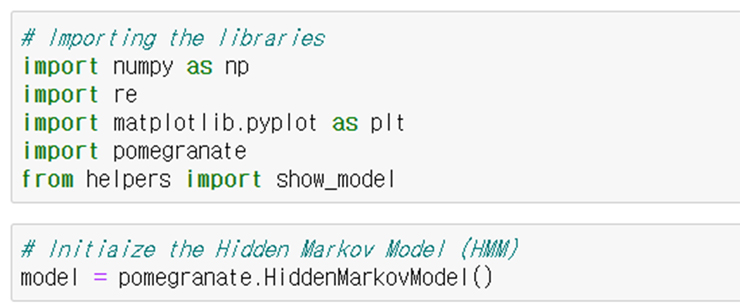
그리고 아래와 같이 품사별 표출 확률들을 pomegranate에 입력해준다.

이러한 상태들이 HMM모델에 추가된다.

전이확률
이제 아래와 같은 전이(transition) 확률을 고려해본다. 각각의 품사가 시작(<S>)에서 출발하여 종착점(<E>)을 향하여, 다음 품사로 전이해갈 확률을 표시하면 아래와 같은 표로 나타낼 수 있다.
![[그림 3. 전이 확률 표]](https://cdn.itbiznews.com/news/photo/202106/39353_35029_2853.jpg)
그리고 이러한 전이 확률을 아래 그림과 같은 마르코프 사슬(Markov Chain)로 표현할 수 있다.
![[그림 4. 전이 확률과 마르코프 사슬]](https://cdn.itbiznews.com/news/photo/202106/39353_35030_2921.jpg)
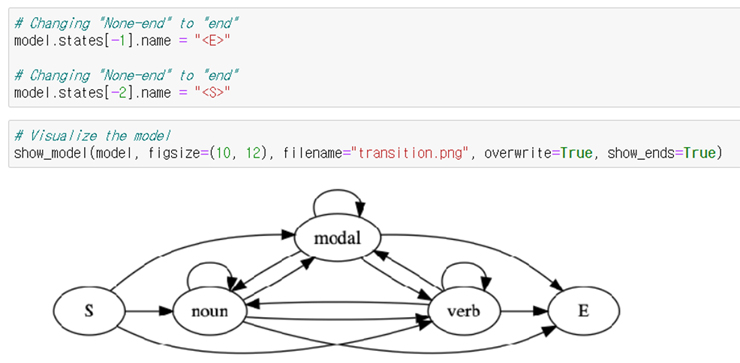
전이 확률들을 model에 추가해주고 모델을 완성한다.

여기에 model.bake()를 통해 모델을 완성하고 모델 상태의 끝에 “<E>”를 그리고 시작에 “<S>”추가한 후, 모델을 시각화한다. 위의 그림 4를 위아래 뒤집어 놓은 그림이 출력됨을 확인함으로써 모델이 성공적으로 수립되었음을 확인한다.
자 그럼 아래와 같은 문장이 있다고 할 때,
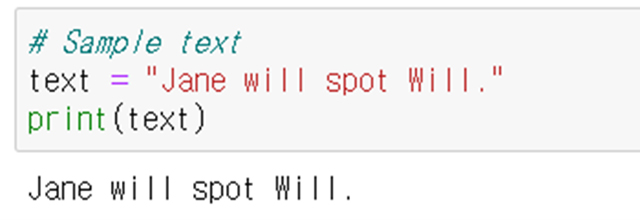
위에서 주어졌던 표출 확률을 기반으로 문장의 품사를 어떻게 예측할 수 있을까?
아래의 그림에서 ①은 왼쪽 위의 테이블에 나타난 바와 같이, will이 M의 상태일 경우에 값이 3/4 임을 가리키고 있으며, ②는 오른쪽 위의 테이블에 표시된 바와 같이, 품사가 <s>에서 시작하는 방향에서 M에서 V 로 이전하는 상태일 경우 3/4 임을 가리키고 있다.
오른쪽 위 상태전이 테이블에서 <S>로부터 시작하여 그 옆의 N 그리고 M -> V 로 한 단계씩 나아가는 과정에서 가장 큰 값을 선택해가면 아래 그림 하단의 굵은 화살표 표시에 나타난 값들이 선택된 것이라는 것을 알 수 있다.
이렇게 선택된 경로가 우리가 구하는 최적화된 품사 예측이다.
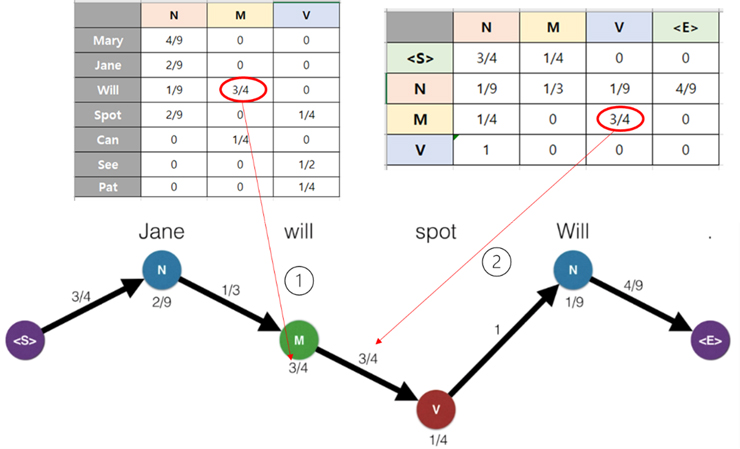
결국, pomegranate.HiddenMarkovModel()의 연산을 통해 Jane will spot Will 이라는 문장의 POS 는 '<S>', 'noun', 'modal', 'verb', 'noun', '<E>' 이라고 찾아낸다.
Pomegranate 의 model.viterbi 함수를 통하여 HMM은 아래와 같은 품사 값을 예측해낸다.

단어가 더 늘어나면 품사(POS) 부여가 단어들 주위의 문맥들로부터 단어의 구문 범주를 결정한다는 점에서 더욱 복잡한 양상을 띄게 된다.
우리가 관측(observation)한 품사별 언급 즉, 명사, 조동사, 동사와 같은 문장 속의 각 단어들이 각각 언급되는 빈도를 가지고 있다고 가정할 경우, 이를 이용하여 간접적으로 은닉(hidden)된 상태, 즉 입력된 문장에 대해 최적화된 품사 구성을 추론하는 문제로 Hidden Markov Model을 통해 답을 구하는 방법을 살펴보았다.
명사(Noun), 조동사(Modal), 동사(Verb) 상호간에 전이표와 언급 횟수를 기반으로 히든마르코프모델을 통한 최적화된 전이확률 발견을 통해 품사를 부여하는 방법이다.
글 : 주철휘 / 인공지능연구소 소장(CAO) / 에이프리카(구 엔쓰리엔클라우드)
관련기사
- 에이프리카, 멀티클라우드 플랫폼 ‘세렝게티 v2.0’ GS인증 1등급 획득
- 엔쓰리엔클라우드, ‘에이프리카’로 사명 변경…AI·클라우드 사업 확대
- 인공지능(AI/ML)이 자연어처리 과정에서 문장의 품사를 알아내는 방법 ①
- “머신러닝(ML) 개발 중 모델 모니터링과 딥러닝(DL) 모델을 동시 개선하는 방법”
- “훈련이 끝난 머신러닝(ML) 모델, 어떻게 서비스 할 수 있을까?”
- “AI개발자들, 주목!”…복수의 GPU를 활용한 분산 훈련 최적화 방법론
- “사용자 친화적인 치타(CHEETAH) 앞세워 ML옵스(ML-Ops) 환경 제시할 것”
- “파괴적 혁신이 주목받는 시대, 인공지능(AI) 뉴노멀 시대로의 전환은 스타트업에게 기회”
- “인공지능(AI) 인프라, 이제 빌려쓴다”…KT, ‘하이퍼스케일’ AI 서비스 출시
- 알리바바그룹, 인공지능(AI) 국제대회 ‘VQA 챌린지’서 1위 기록